Fig.1. Algorithm Flow Chart
摘要:
目前傳統監視攝影系統雖然具有“監視“的效果,不過卻都是等到事故發生時,才利用人眼判斷過濾影片中的可疑事物,這樣的做法只是亡羊捕牢,完全無法降低意外發生的損失。有鑑於傳統監視系統的被動性,我們提出一套新的“智慧型監視系統“,它能夠分析畫面中的移動事物,進一步判別此事物否具有危險性,並主動告知管理人員,讓管理人員能夠在第一時間制止這類事情的發生,降低損失。另外在犯罪發生後,我們要找到犯人變得更快了,因為我們只要做類似google search之類的搜尋動作即可,不必大量的觀看所有的錄影。一般而言,智慧型的監視系統的主要功能都基於三個基本功能,分別為視訊物件的分割、物件的描述及物件的追蹤。這裡要介紹的演算法,是一個可以同時達到視訊物件的分割、描述及追蹤效果的單一演算法。
Abstract:
Segmentation, tracking, and description extraction are important operations in smart camera surveillance systems. A robust segmentation-and-descriptor based tracking algorithm is introduced here. Segmentation is applied first, and description for each connected component is extracted for object classification to generate the video object masks. It can do segmentation, tracking, and description extraction with a single algorithm without redundant computation. In addition, a new descriptor for human objects, Human Color Structure Descriptor (HCSD), is also proposed for this algorithm. Experimental results show that the proposed algorithm can provide precise video object masks and trajectories. It is also shown that the proposed descriptor, HCSD, can achieve better performance than Scalable Color Descriptor and Color Structure Descriptor of MPEG-7 for human objects.
演算法簡介:
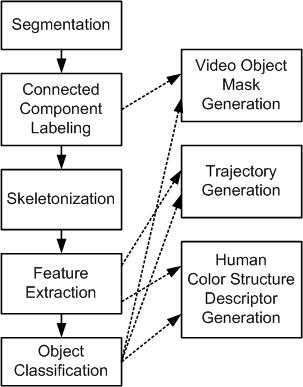
這個演算法可以由下圖(Fig. 1)來表示,它分為幾個步驟,以下就依序分別介紹:
HCSDi = {(cib, pib), (cil, pil), (cis)}, ............................................................................................................................................(1)
其中cib, cil, and cis, 記錄的是人類物件i上衣、褲子及鞋子的顏色,而 pib and pil 記錄的是物件i軀幹及下肢所在的位置 .
Fig.1. Algorithm Flow Chart

Fig. 2. An example from segmentation step to skeletonization step, where the test sequence is Hall Monitor.
Algorithm Overview:
In this section, a segmentation-and-descriptor based tracking algorithm, which can do segmentation, description extraction, and tracking with a single algorithm without redundant computation, is proposed. The flow of the proposed algorithm is shown in Fig. 1, and an example is given in Fig. 2. The extraction process of the proposed descriptor, HCSD, is also shown in the flow of Fig. 1. First, the source surveillance video is segmented into background and foreground video objects, in which the object mask is produced [1]. Second, each object will be given an unique label in the connected component labeling step. Thirdly, each object will be decomposed into several meaningful parts in the skeletonization step by morphological skeleton transform [2]. Especially for the human objects, the head, body, hands and legs could be separated apart. Benefited from the skeletonization step, the color feature and the position of each part can be extracted in the feature extraction step. Besides, the size of each object is also extracted in this step. The extracted features can then be grouped to form HCSD, which can be represented with the following form : For an object i,
HCSDi = {(cib, pib), (cil, pil), (cis)}, ................................................(1)
where cib, cil, and cis, are the colors of body, legs, and shoes of human object i, respectively, and pib and pil are the positions of body and legs of the object.
Finally, with the features extracted in the feature extraction step, the objects detected in each frame can be simply classified, and the correspondences between the objects detected in the current frame and those detected in the previous frames can be easily built in the object classification step, in which the video object tracking is done, and the trajectories of the video objects are produced as well.
Demo Sequences:
Sequence Name |
Original Sequence |
Demo Sequence |
Hall_cif |
||
Outside_Library |
發表過的相關論文(Published Papers):
參考文獻(Reference):