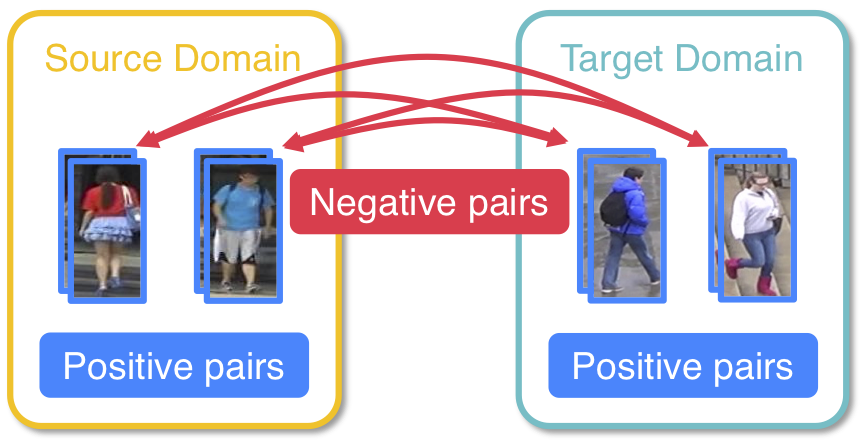
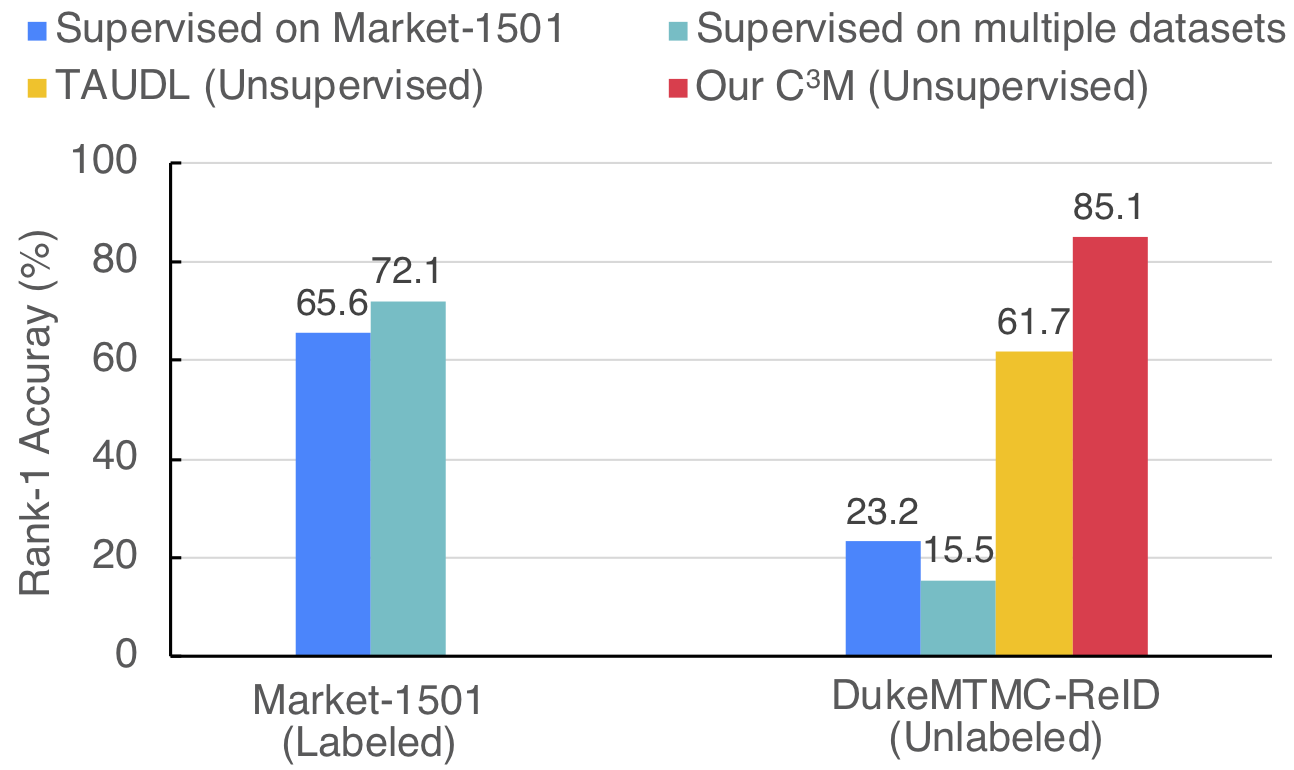
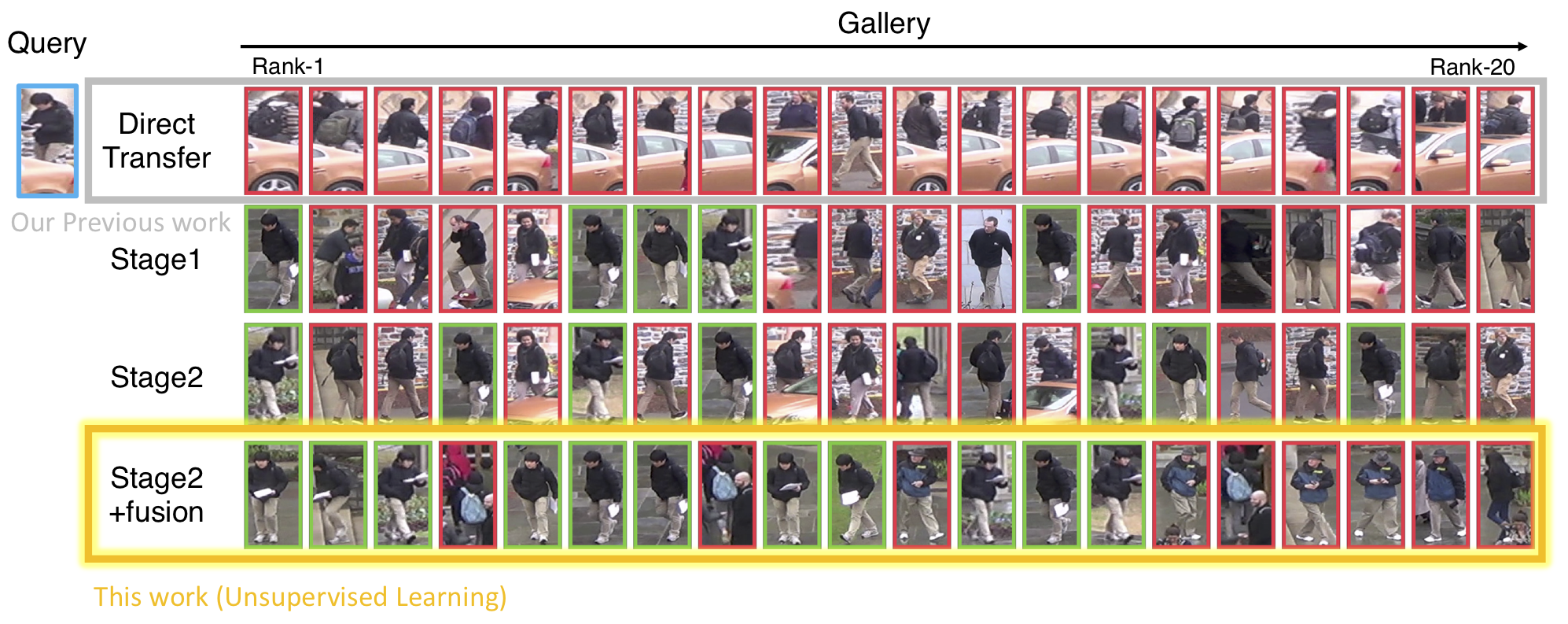
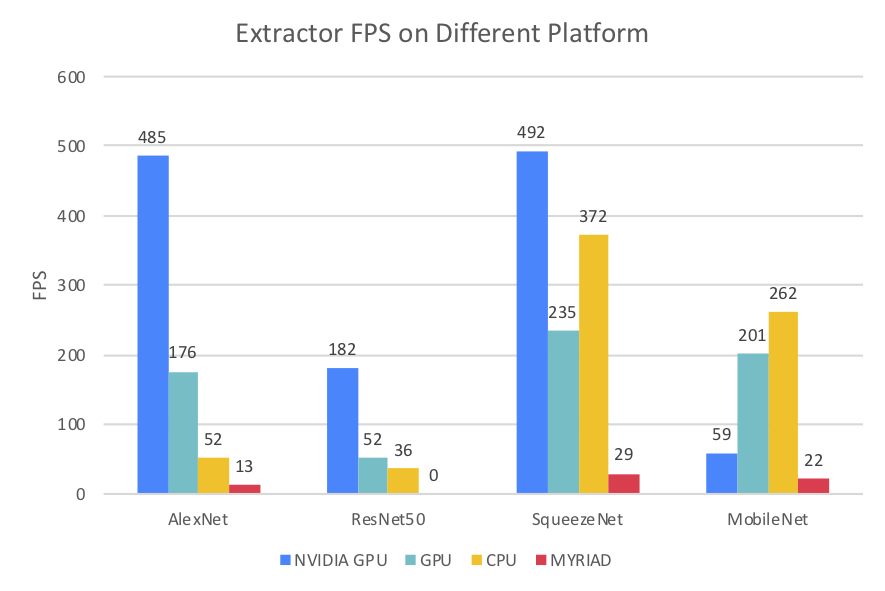
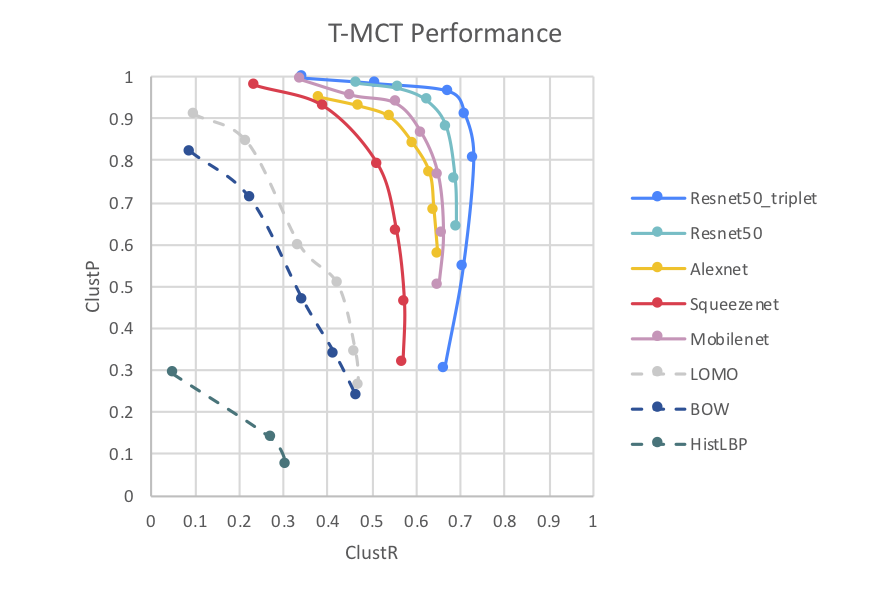
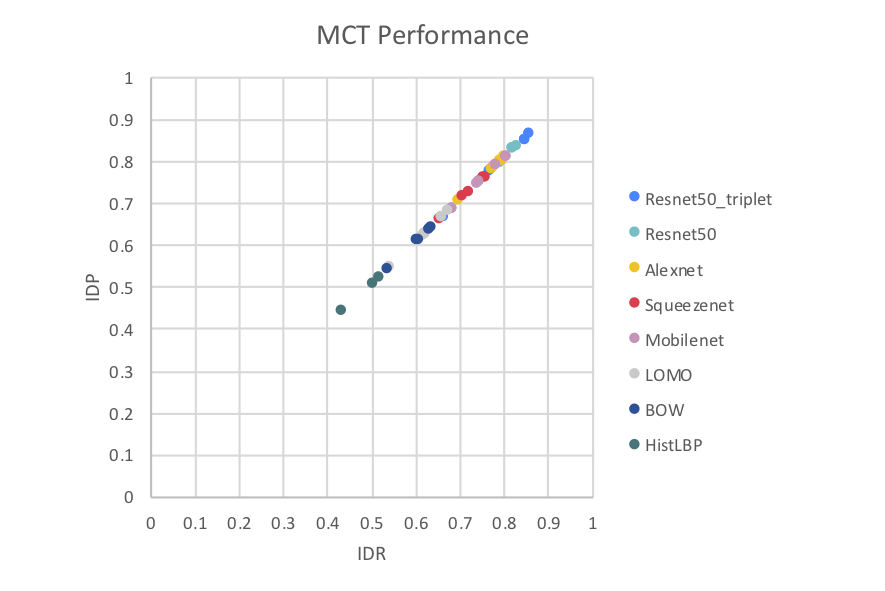
Introduction
What is the task?
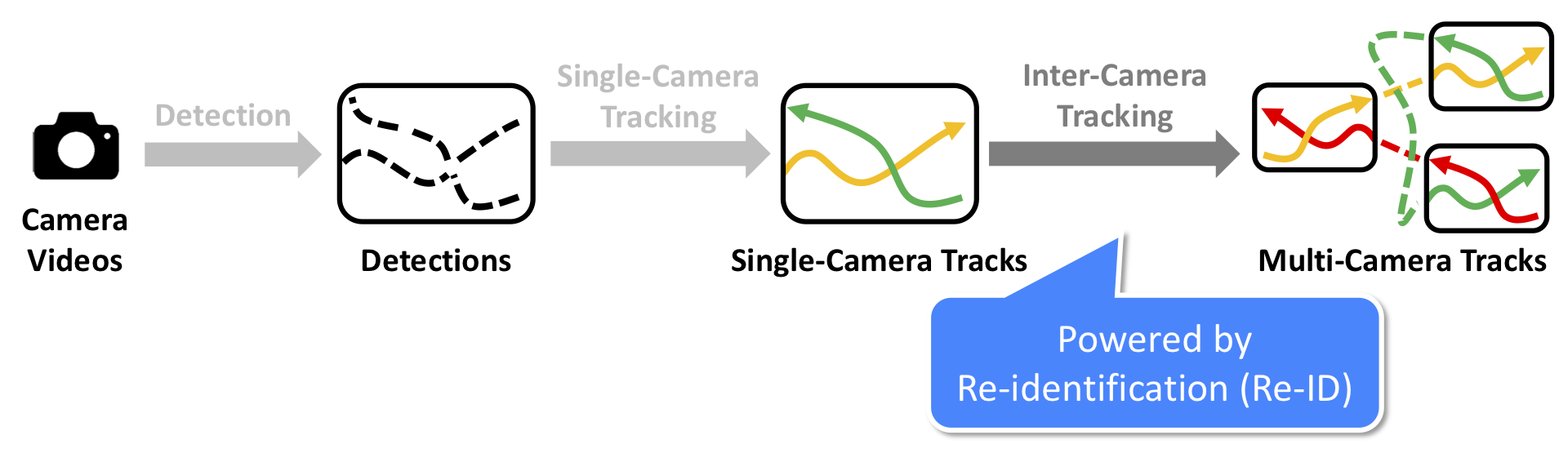
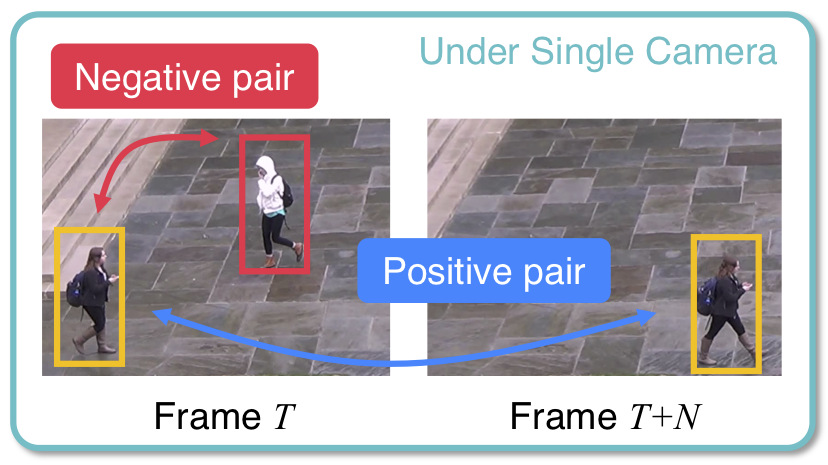
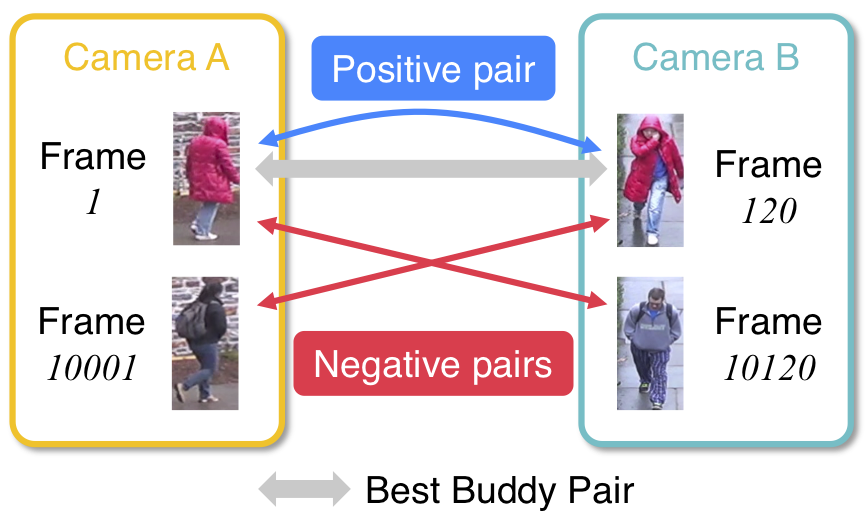
In this thesis, we try to solve the problem of Multi-Camera Tracking (MCT). Multi-Camera Tracking aims to track multiple targets in a camera network. Specifically, we focus on tracking pedestrians as our priority target. Multi-Camera Tracking is the critical underlying technology for building large-scale intelligent surveillance systems. Building such complex systems requires solving some of the hardest task in computer vision, including detection, single-camera tracking (also known as visual object tracking, multi-object tracking), inter-camera tracking and re-identification.

What is the motivation?
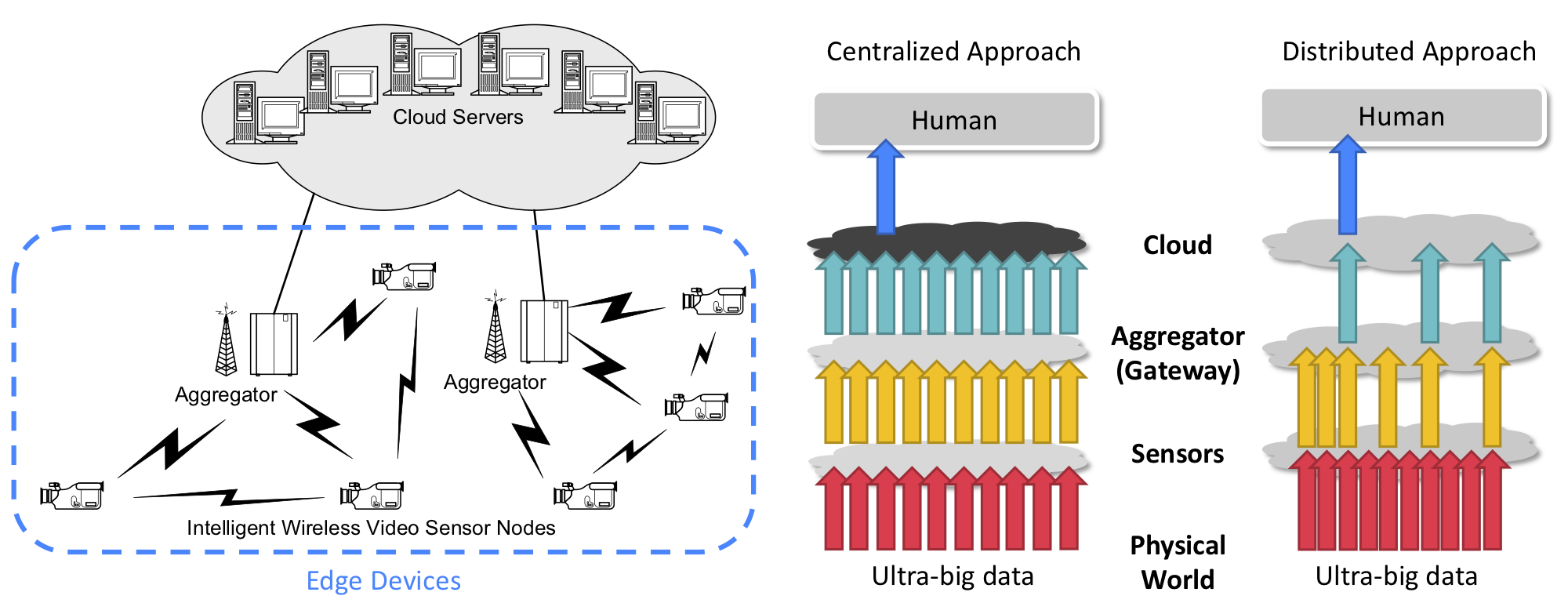
As a large-scale intelligent surveillance system typically connects thousands of camera, a tremendous amount of video data is collected every second by machines. However, such amount of data could potentially overwhelm even the most capable machines if not processed efficiently. Therefore, it is critical for us to develop efficient ways to extract useful information from the videos. A typical approach for surveillance systems is to stream all videos to a central server and perform analysis all at once on the server. Yet, such approach not only put extensive stress on the central server but also requires expensive bandwidth to transmit high-resolution videos from edge to the server. Therefore, we aim to develop a distributed solution to process the videos in contrast to the traditional centralized approach.