We propose a system for real-time six degrees of freedom
(6DoF) tracking of a passive stylus that achieves submillimeter
accuracy, which is suitable for writing or drawing
in mixed reality applications. Our system is particularly easy
to implement, requiring only a monocular camera, a 3D printed
dodecahedron, and hand-glued binary square markers. The
accuracy and performance we achieve are due to model-based
tracking using a calibrated model and a combination of sparse
pose estimation and dense alignment. We demonstrate the system
performance in terms of speed and accuracy on a number
of synthetic and real datasets, showing that it can be competitive
with state-of-the-art multi-camera motion capture systems.
We also demonstrate several applications of the technology
ranging from 2D and 3D drawing in VR to general object
manipulation and board games.
Po-Chen Wu, Robert Wang, Kenrick Kin, Christopher Twigg, Shangchen Han, Ming-Hsuan Yang, and Shao-Yi Chien,
"DodecaPen: Accurate 6DoF Tracking of a Passive Stylus."
In Proceedings of the ACM Symposium on User Interface Software and Technology (UIST), 2017.
Bibtex
@inproceeding{DodecaPen2017,
author = {Wu, Po-Chen and Wang, Robert and Kin, Kenrick and Twigg, Christopher and Han, Shangchen and Yang, Ming-Hsuan and and Chien, Shao-Yi},
title = {DodecaPen: Accurate 6DoF Tracking of a Passive Stylus},
booktitle = {ACM Symposium on User Interface Software and Technology (UIST)},
year = {2017}
}
Demo
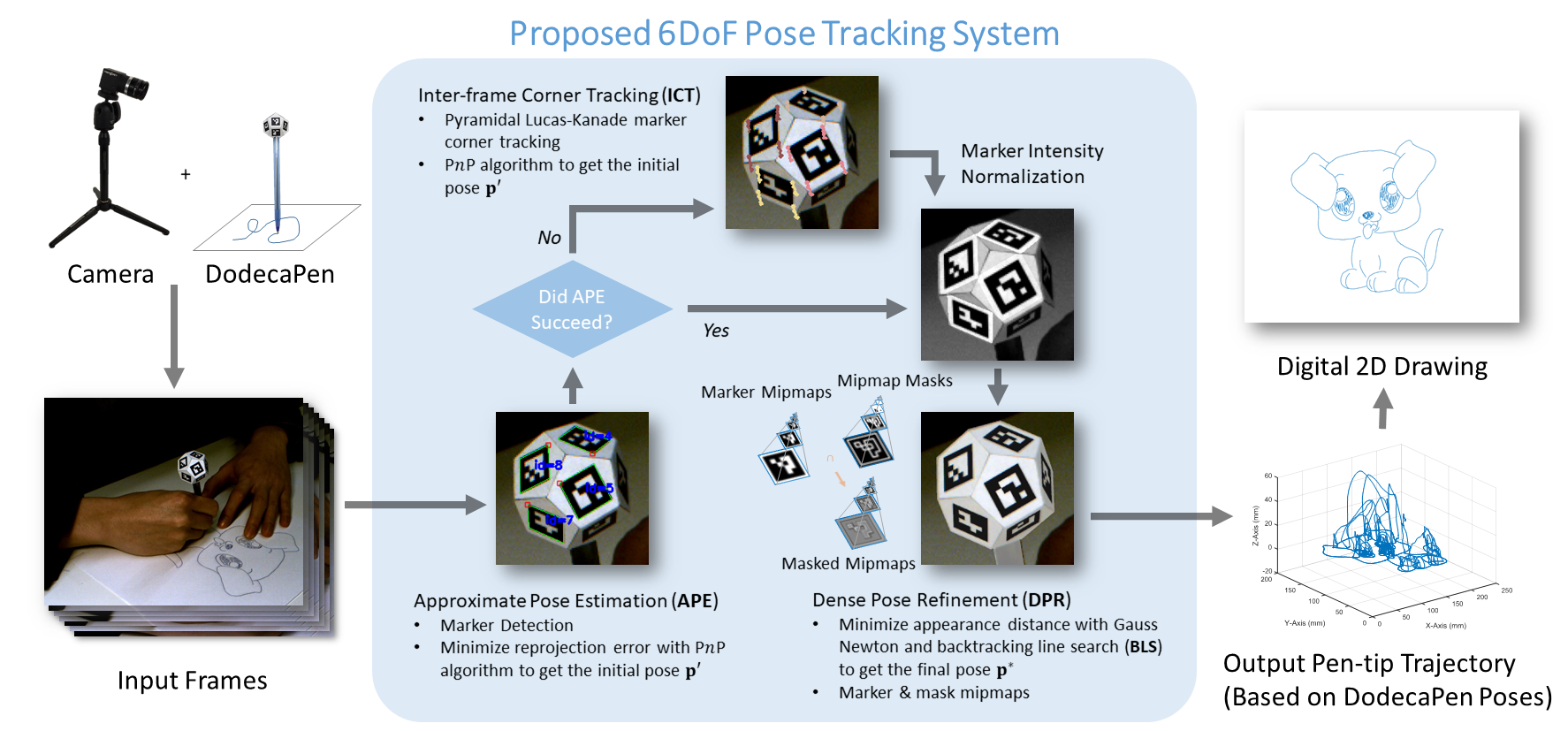
System Overview
In the approximate pose estimation step,
we detect the binary square fiducial markers in the input images,
and estimate the 6DoF pose of the DodecaPen using the PnP algorithm.
If fewer than two markers are detected,
we use the LK method to track marker corners between frames.
In the dense pose refinement step, the pose p'
is refined by minimizing the appearance distance between the 3D model of the DodecaPen
and image pixels to get the final pose p*.
We generate the pen-tip trajectory in the 3D view from the computed 6DoF pose sequence,
and visualize the 2D drawing by removing points where the pen tip is lifted off the page.
Results
Dataset
Synthetic
Real
Frame Width
1280
1280
Frame Height
1024
1024
Frame Rate
30
60
Focal Length fx
2401.277
2425.167
Focal Length fy
2401.277
2425.167
Principle Point cx
642.597
682.062
Principle Point cy
558.038
566.282
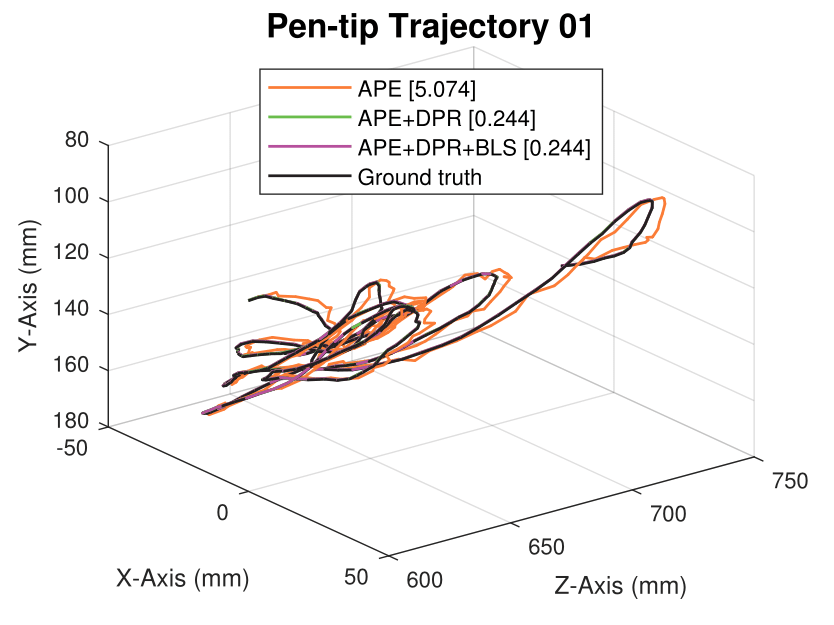
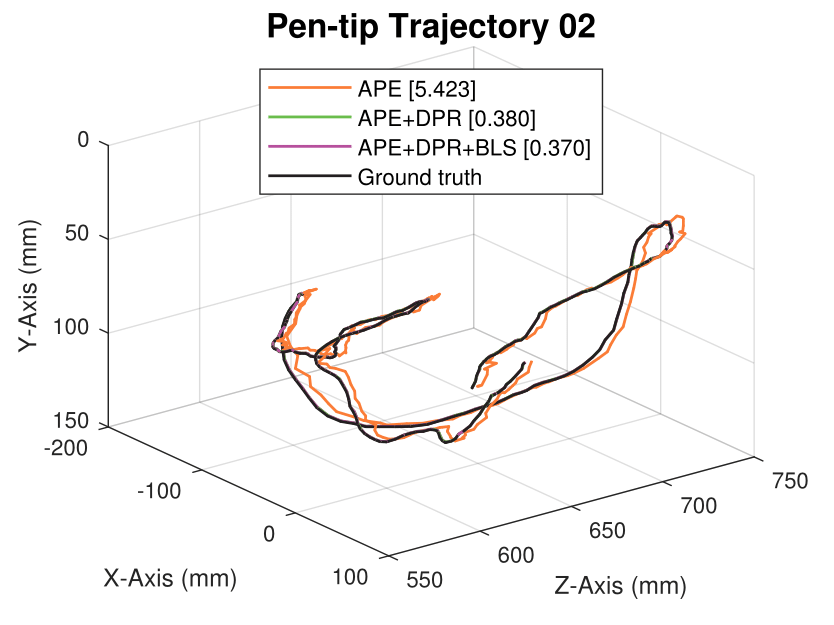
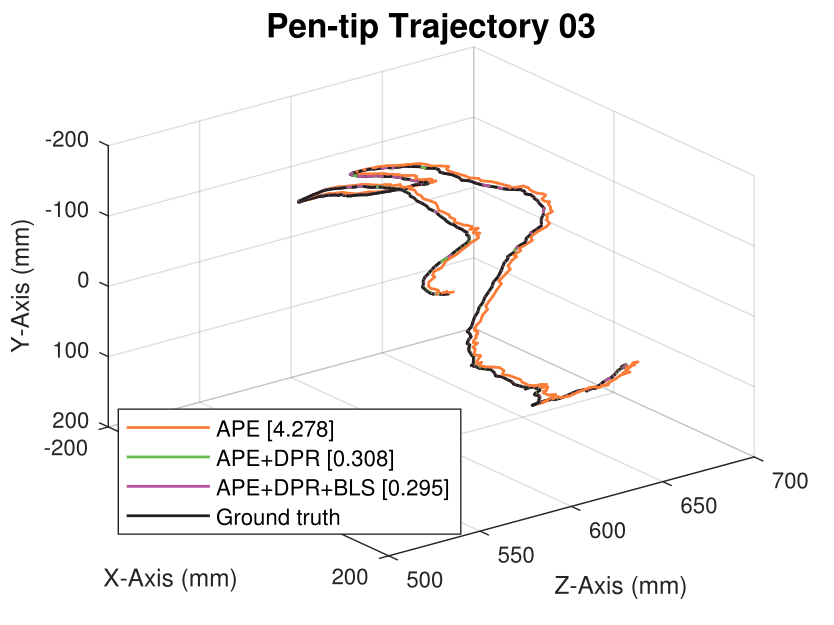
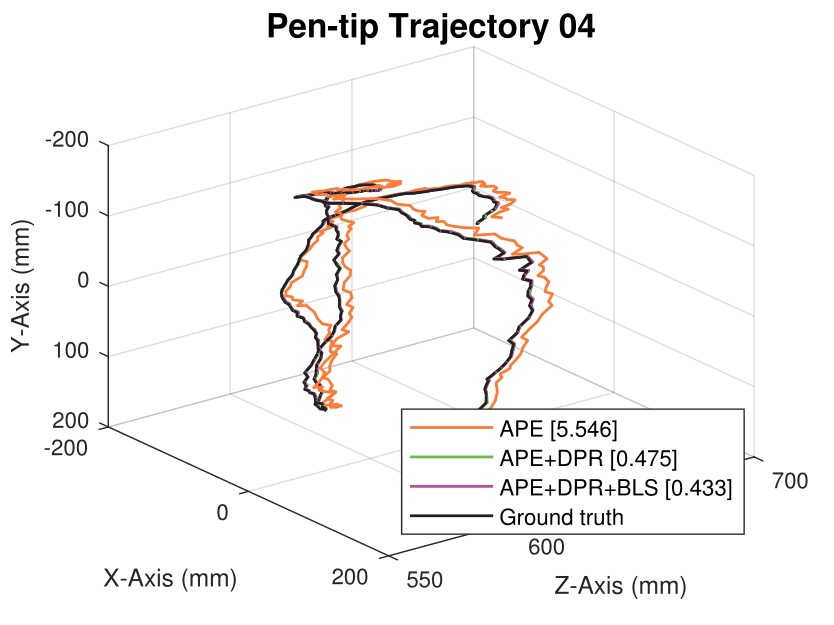
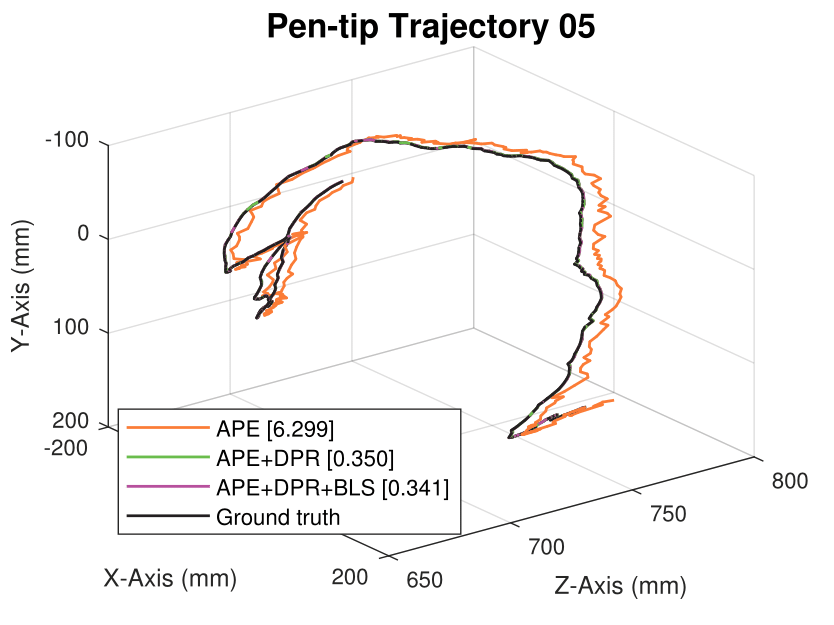
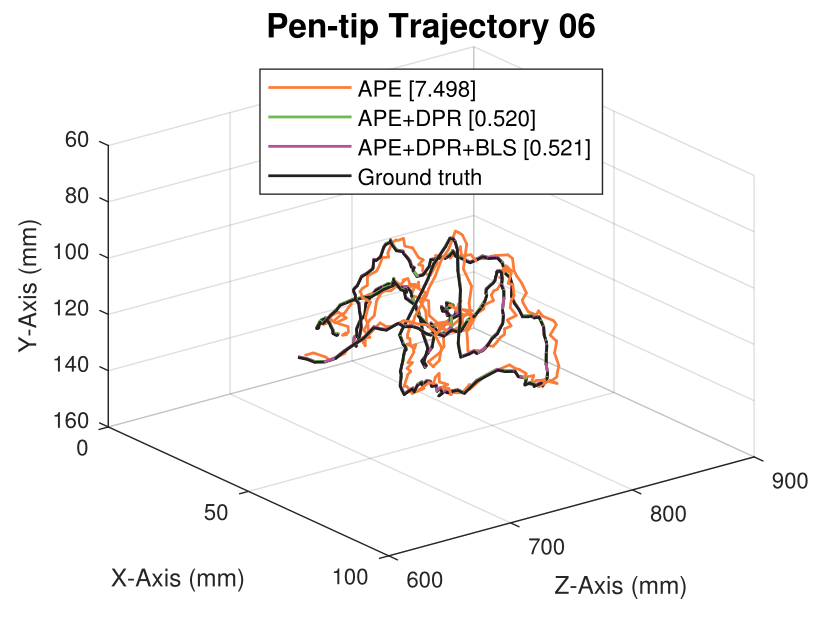
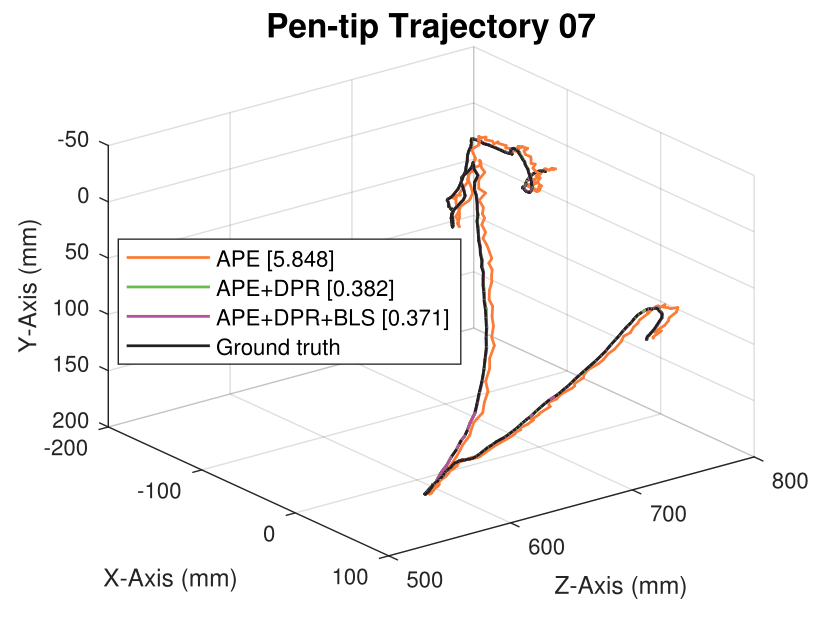
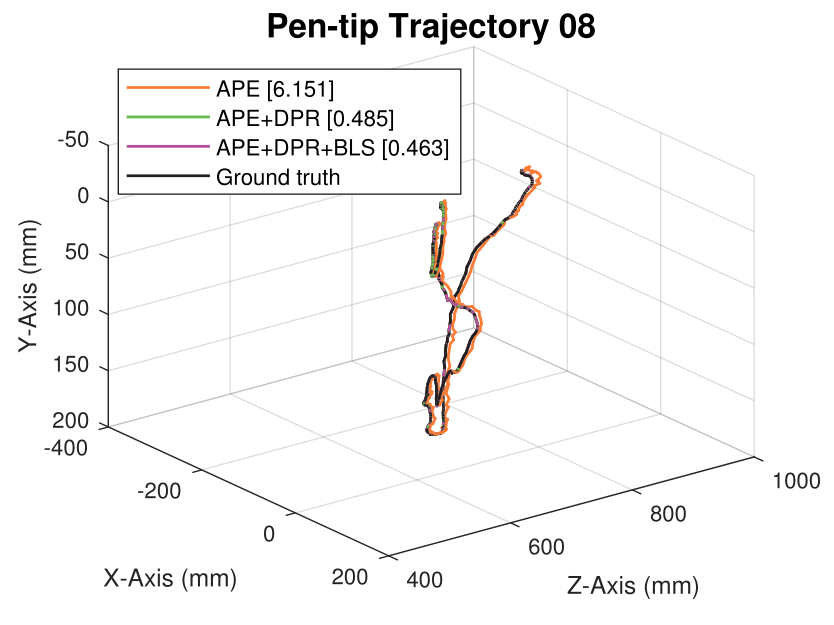
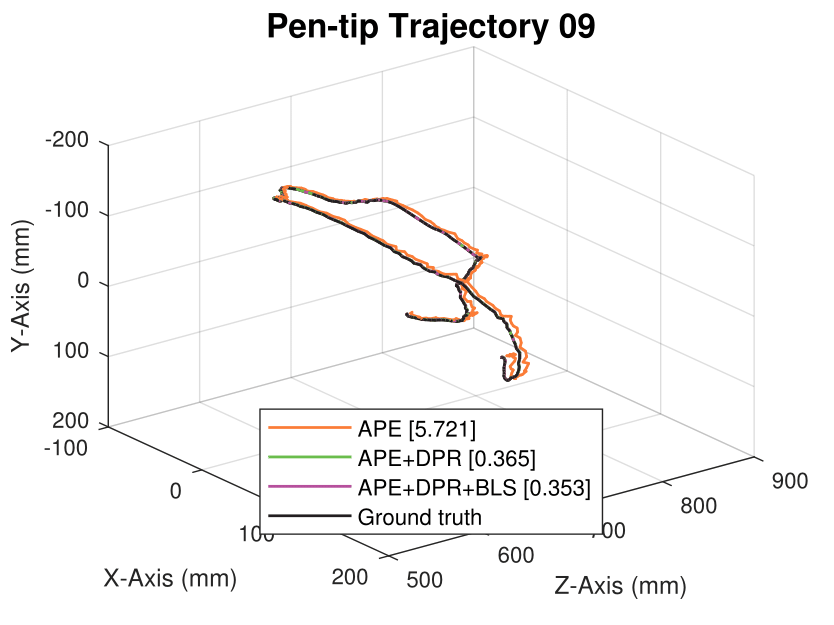
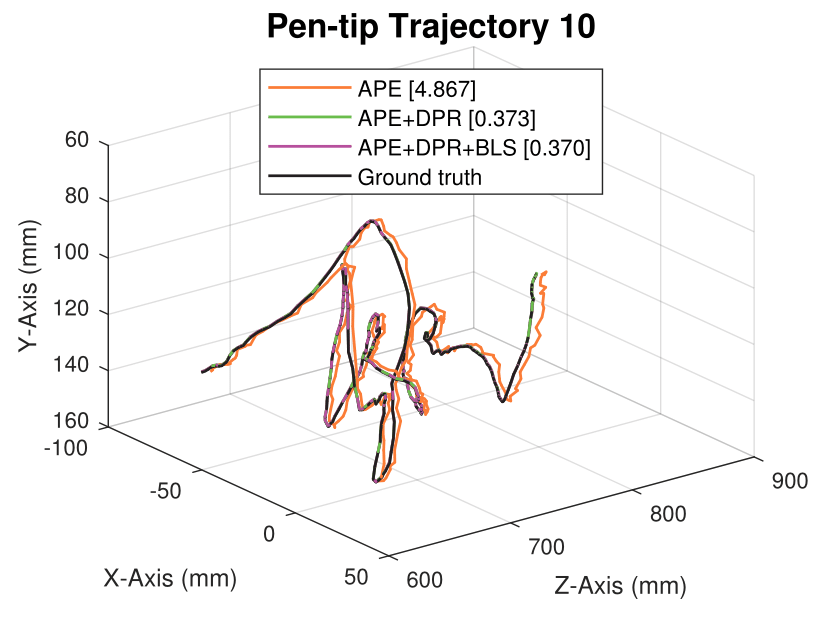
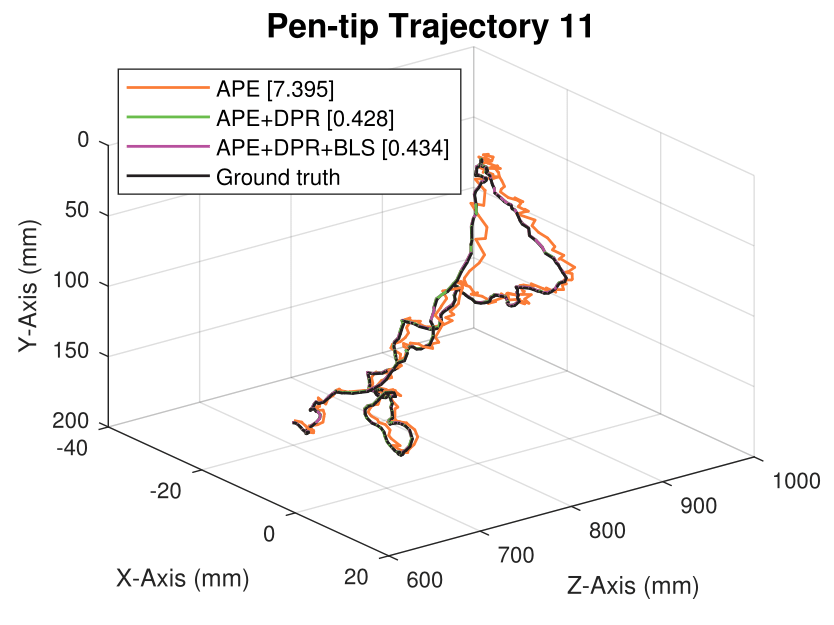
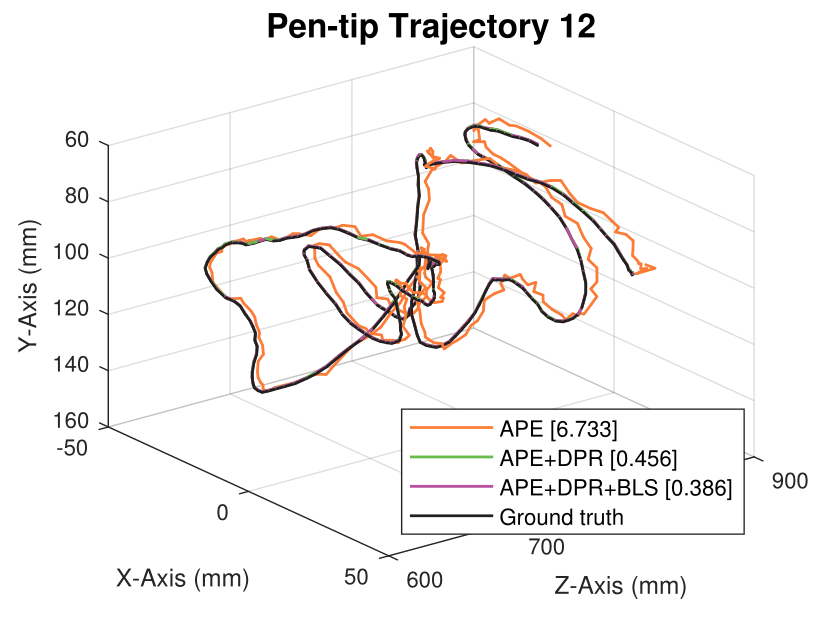
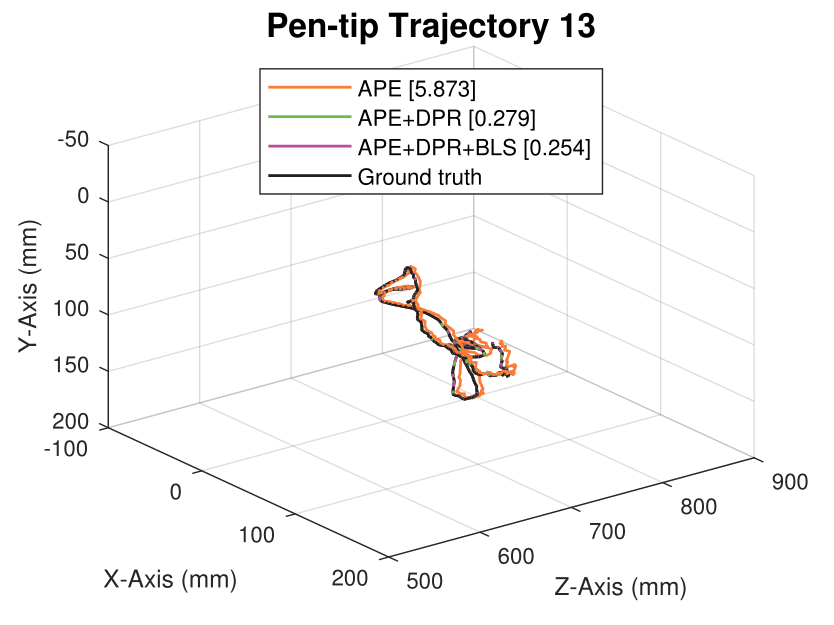
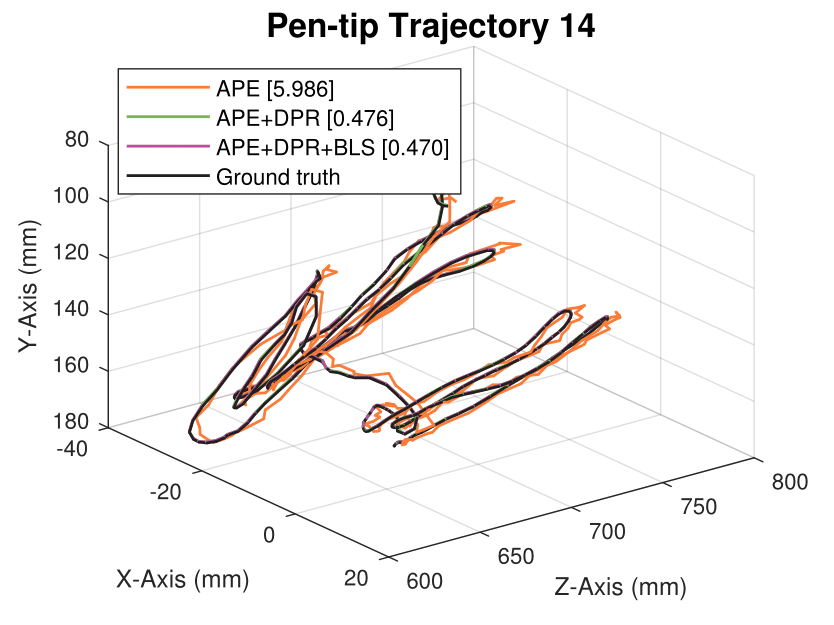
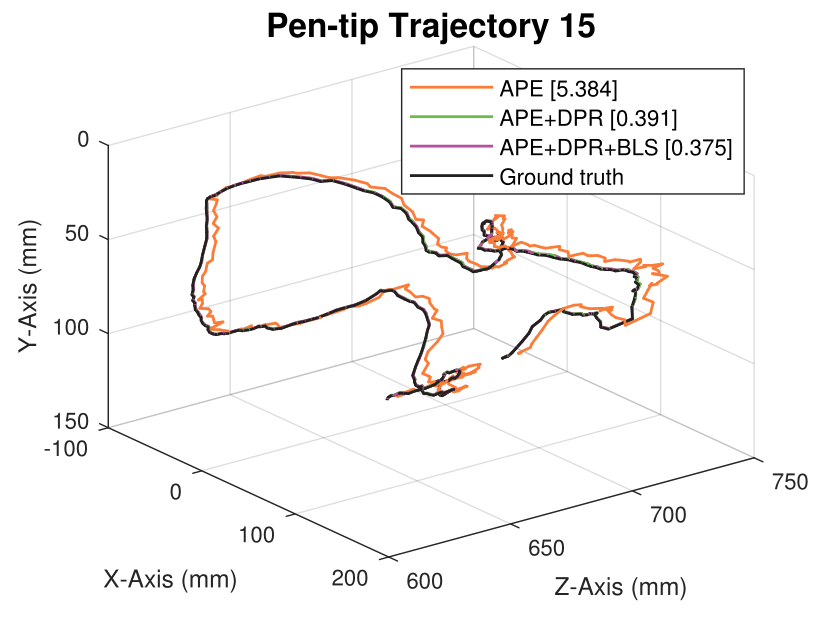
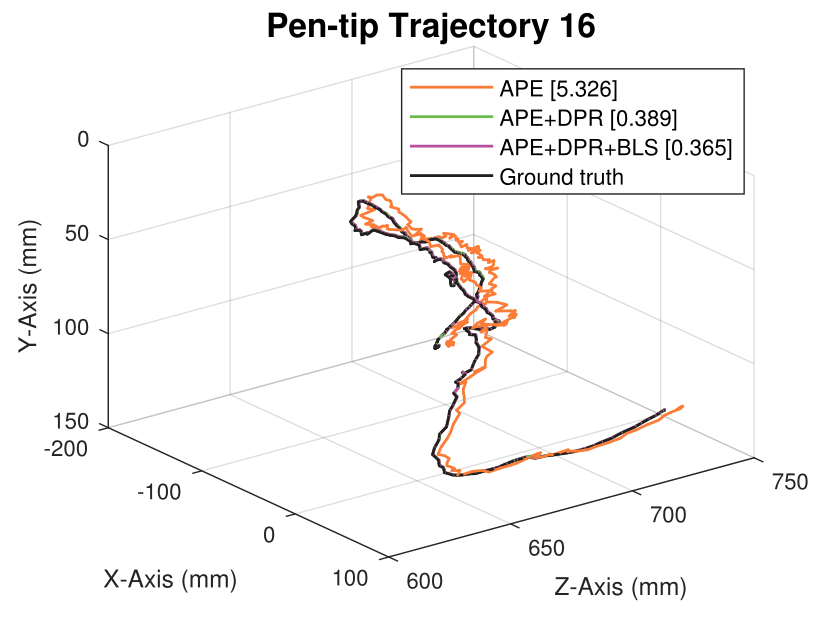
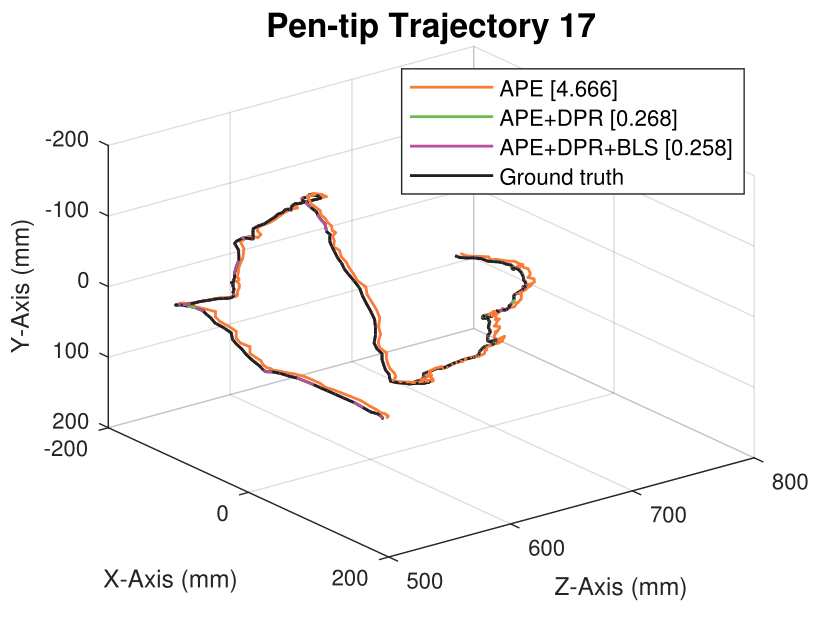
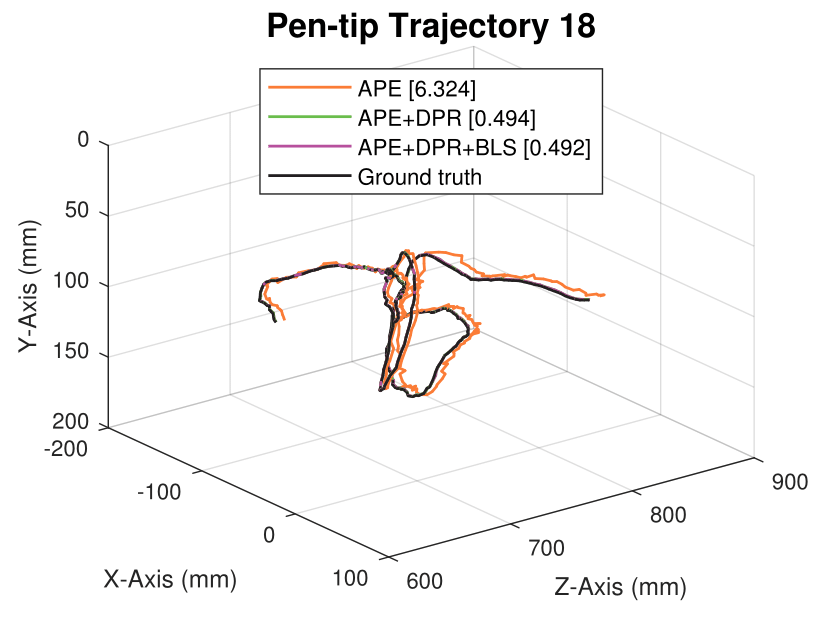
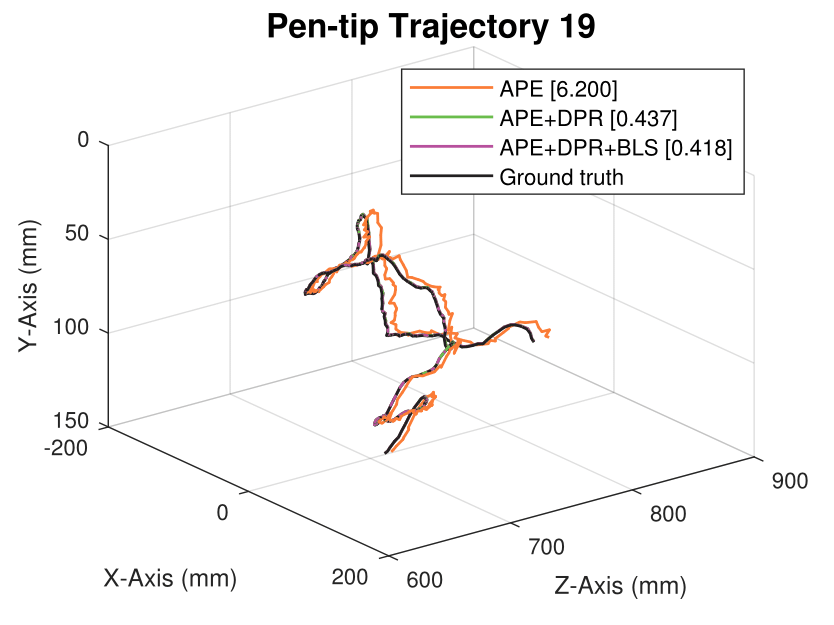
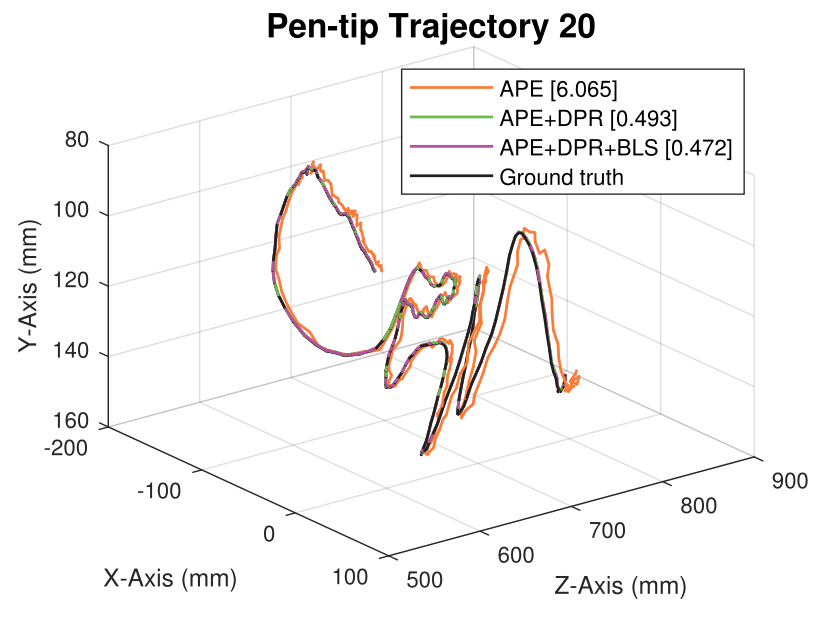
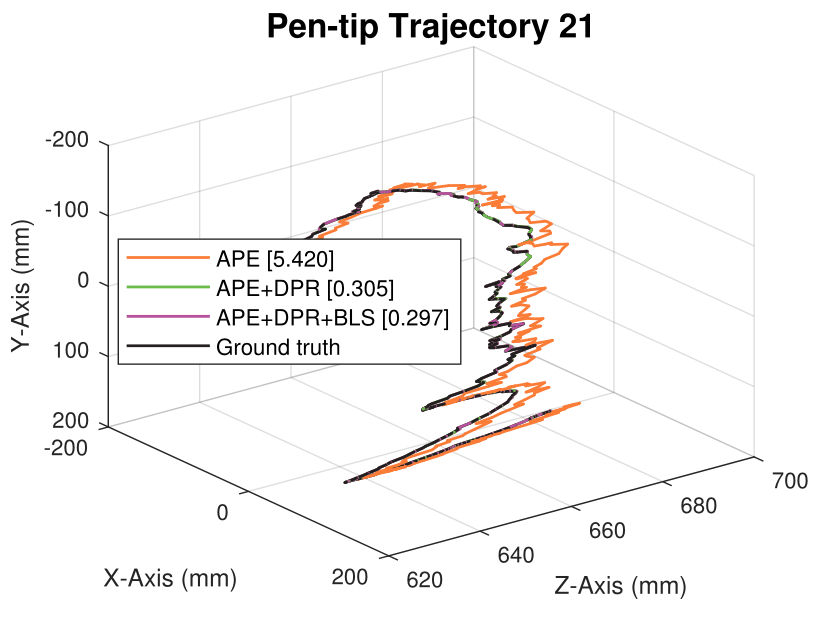
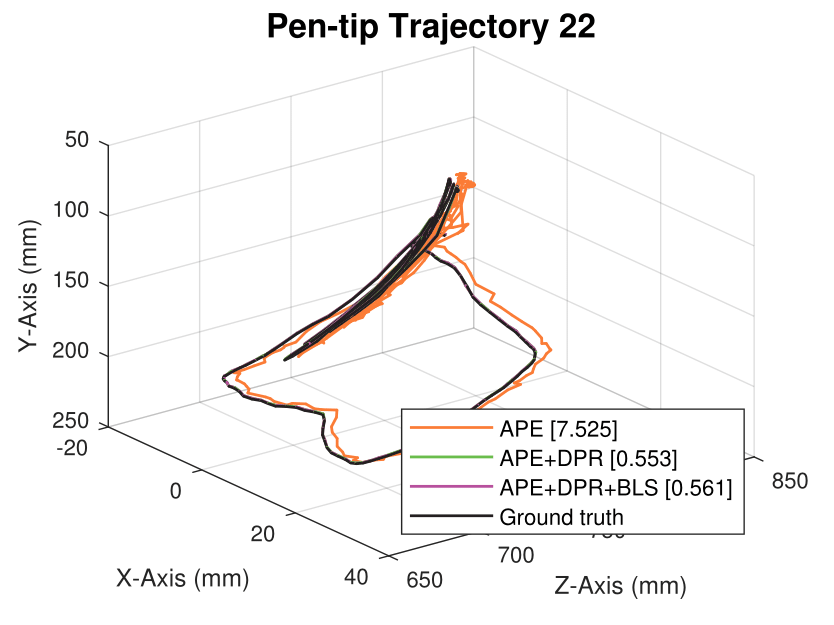
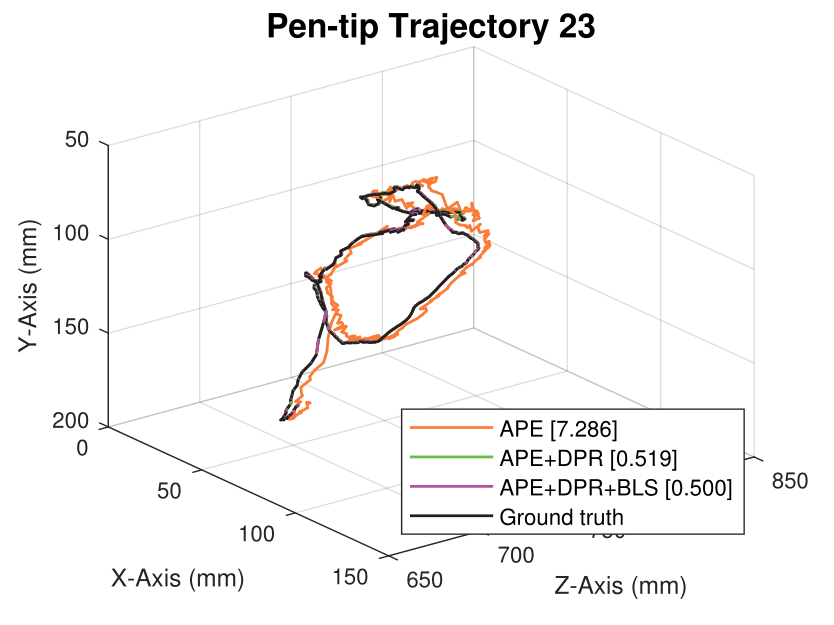
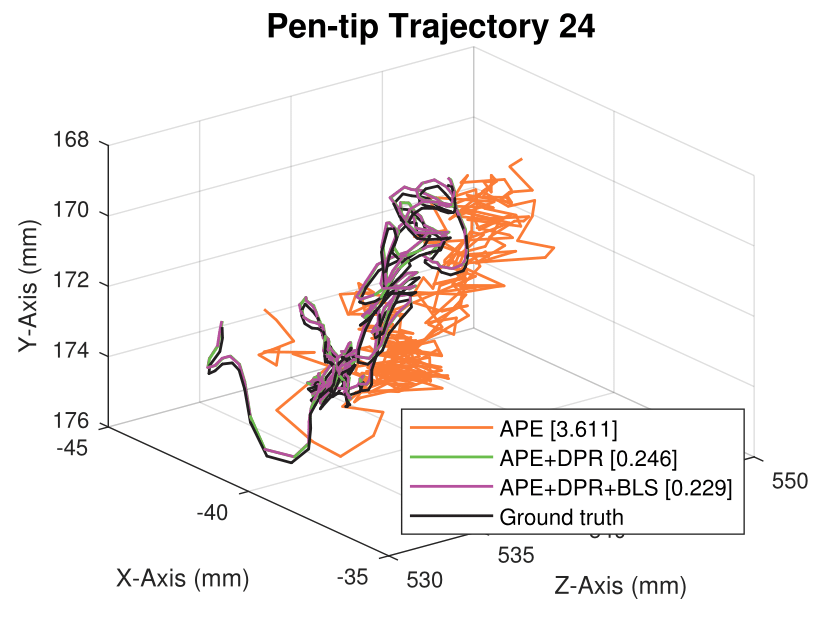
We generate synthetic image sequences with 24 motion patterns of the virtual DodecaPen for evaluation.
Average pen-tip errors (mm) are shown in legends.
Seq. 01
Seq. 02
Seq. 03
Seq. 04
Seq. 05
Seq. 06
Seq. 07
Seq. 08
Seq. 09
Seq. 10
Seq. 11
Seq. 12
Seq. 13
Seq. 14
Seq. 15
Seq. 16
Seq. 17
Seq. 18
Seq. 19
Seq. 20
Seq. 21
Seq. 22
Seq. 23
Seq. 24
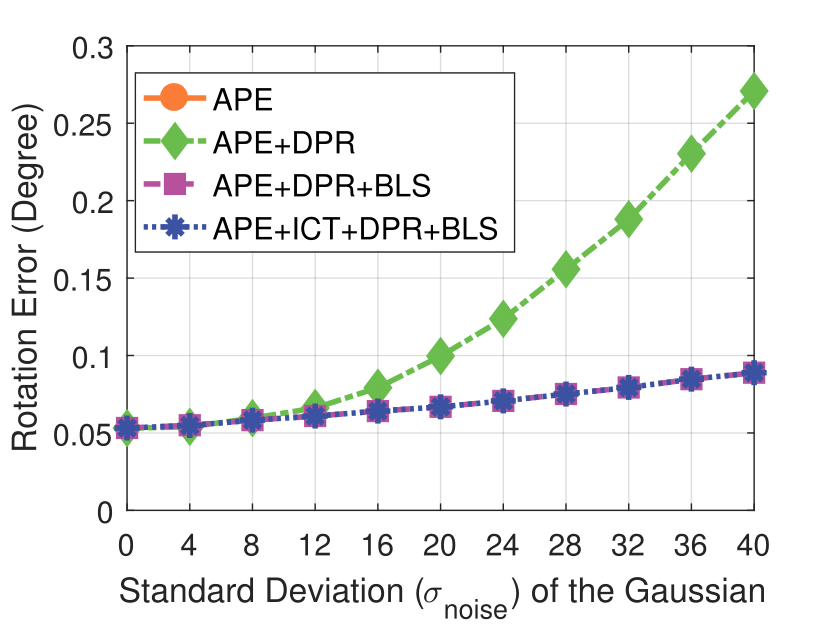
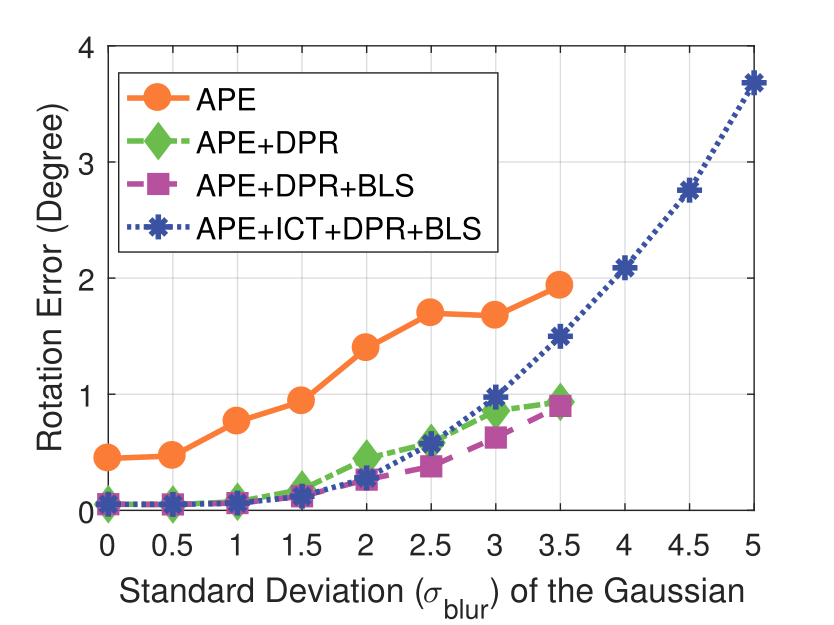
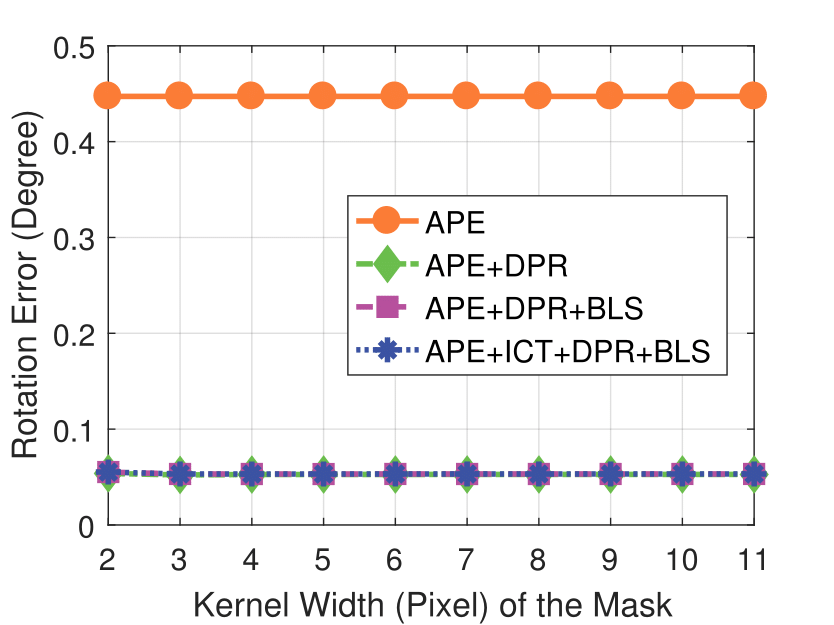
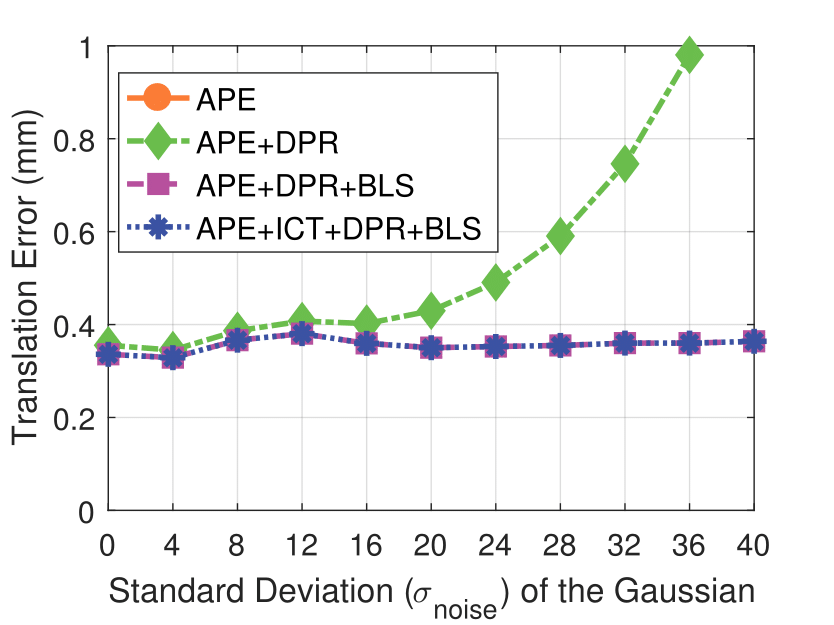
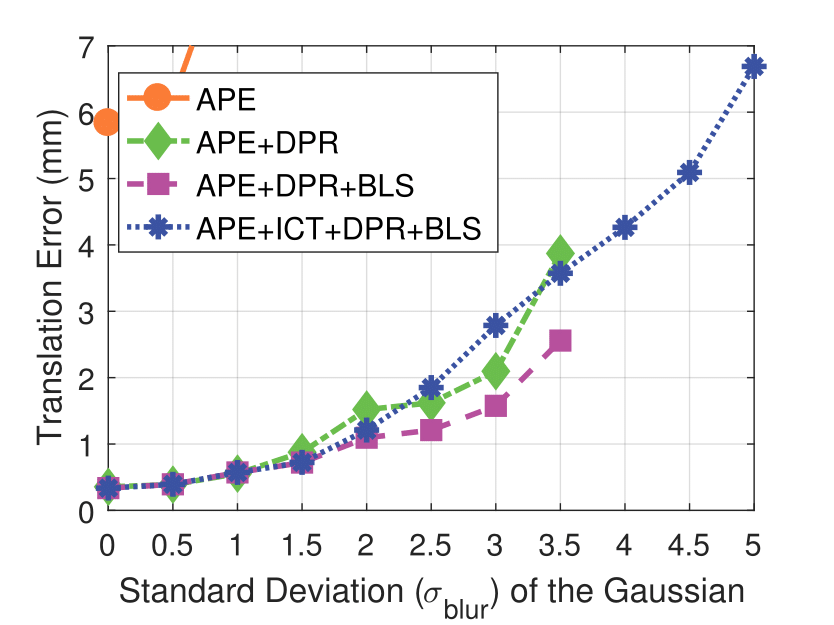
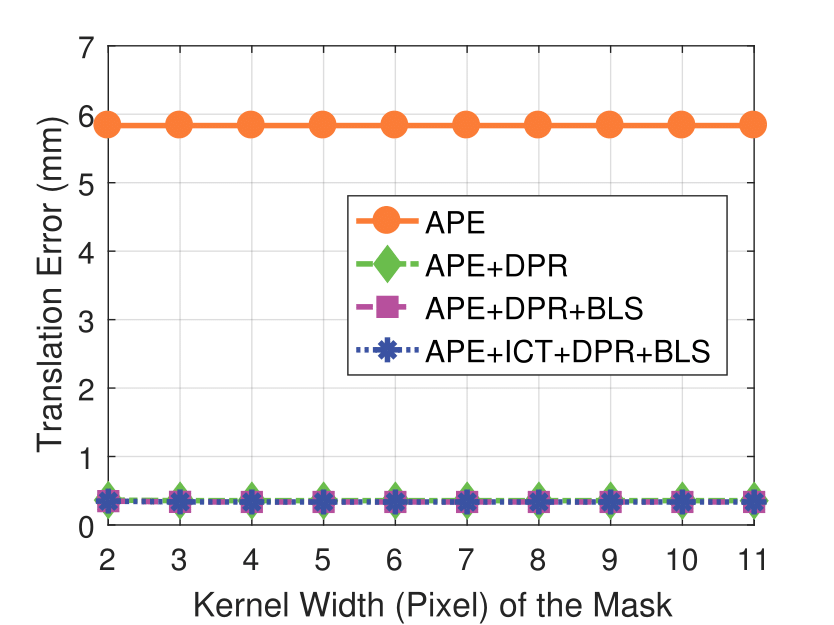
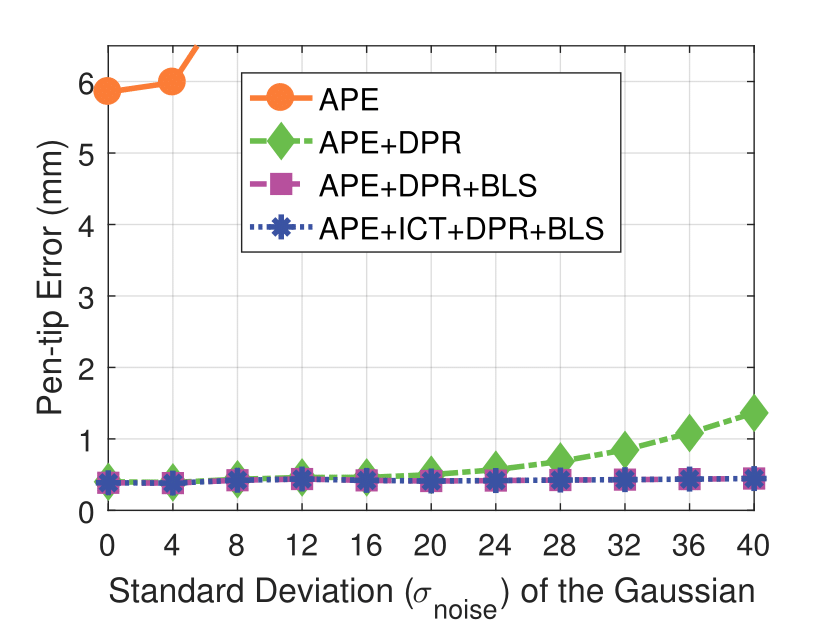
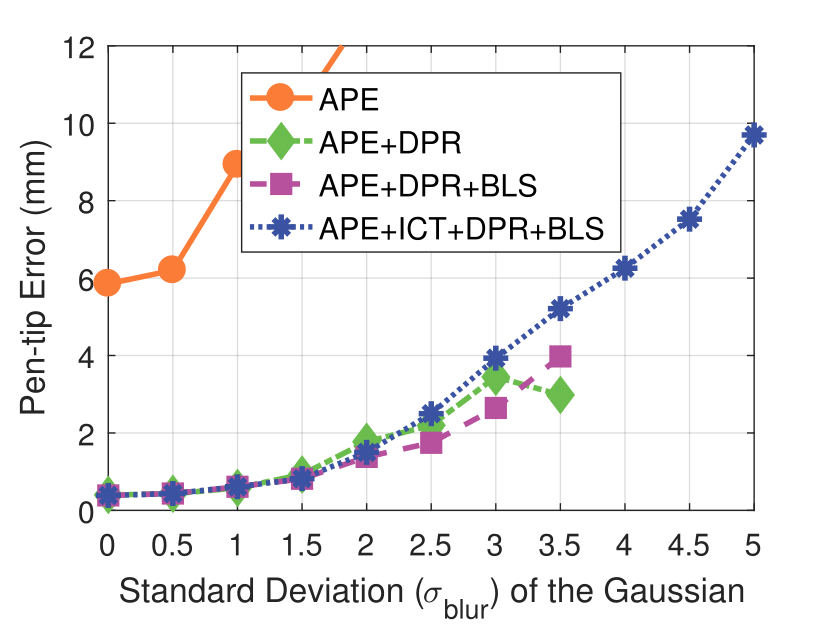
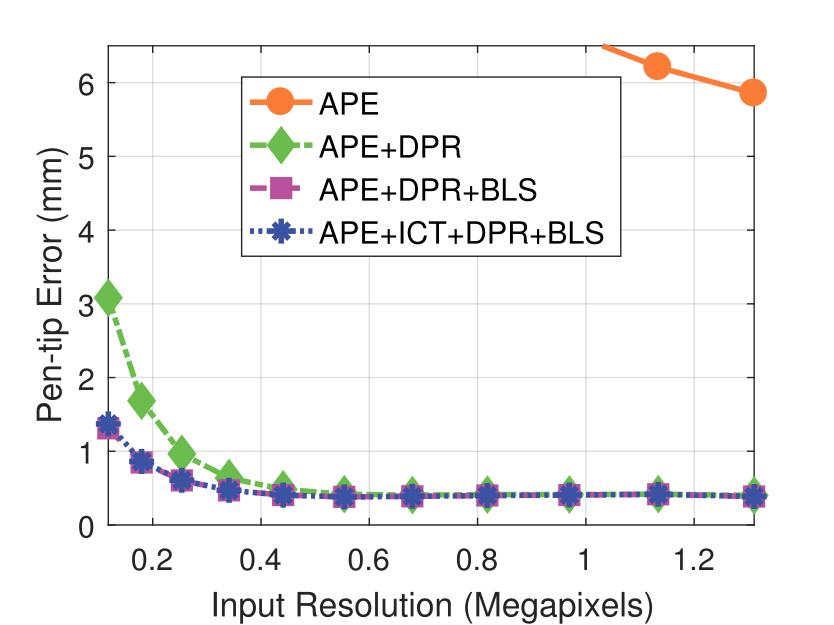
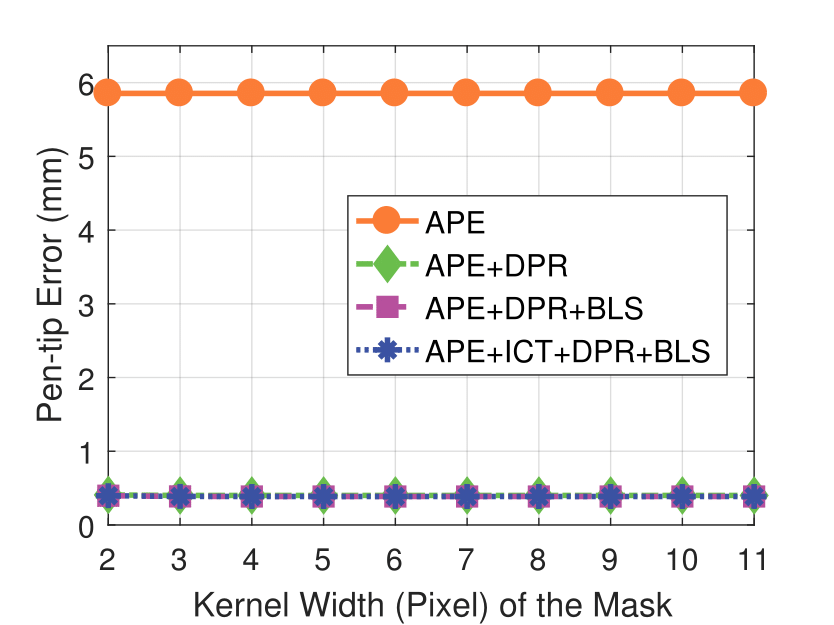
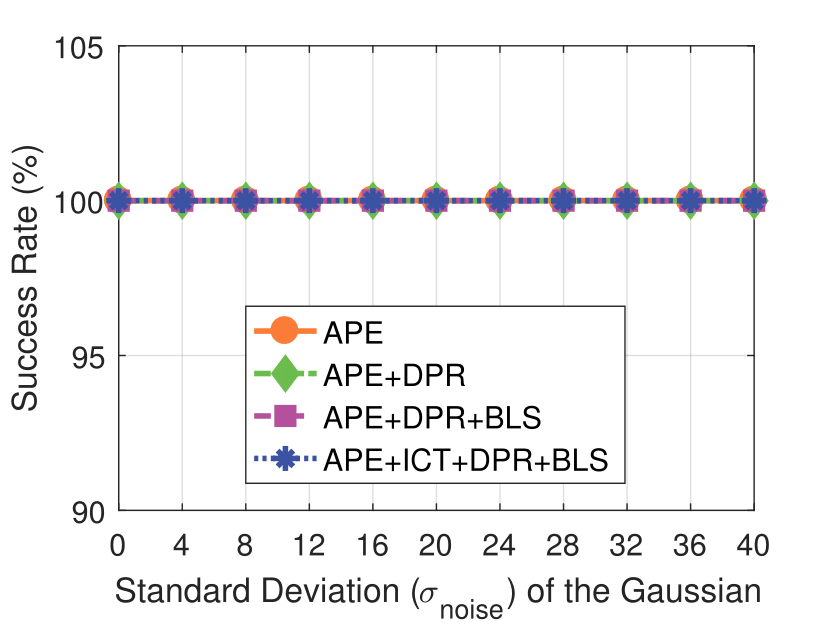
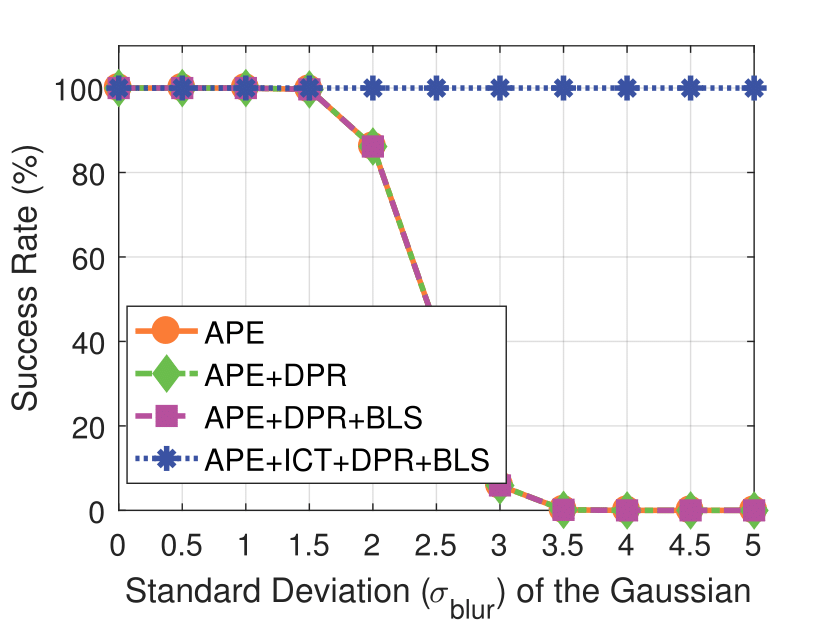
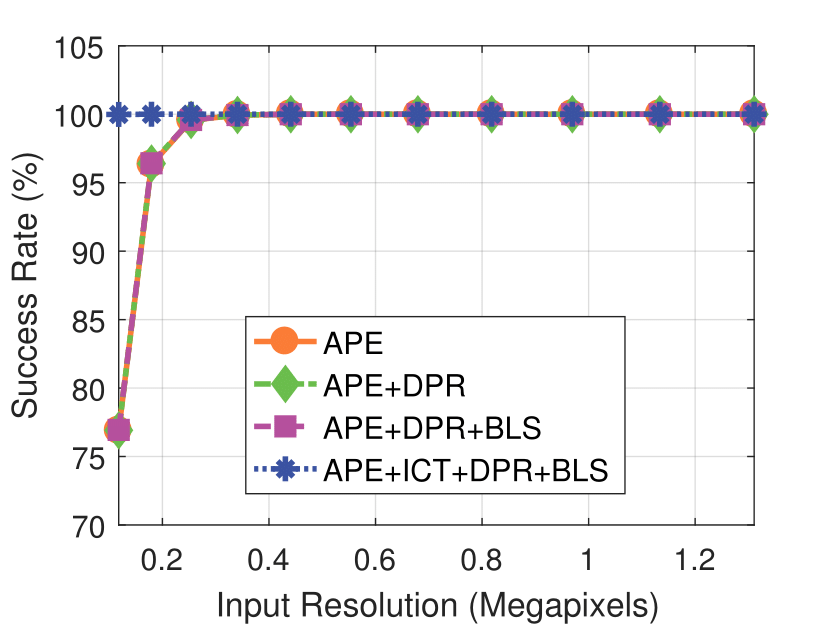
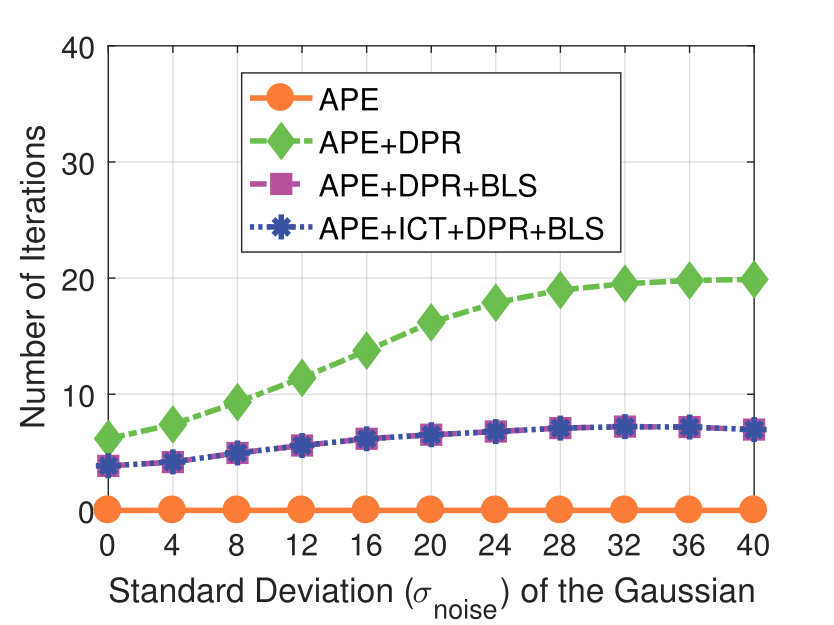
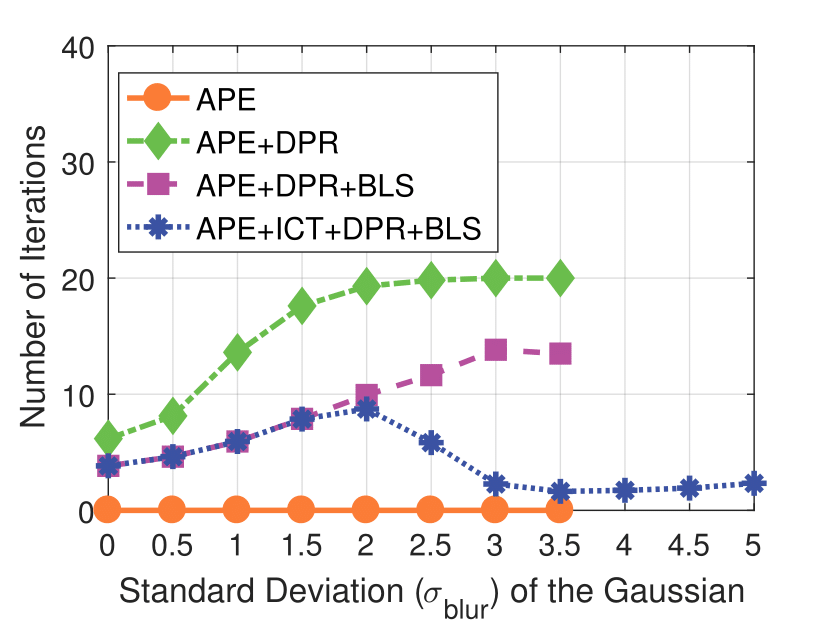
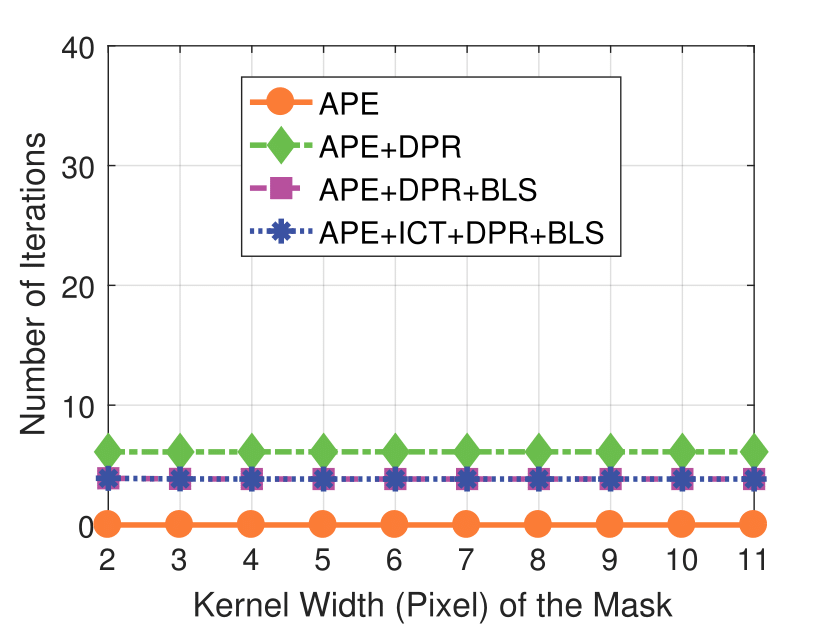
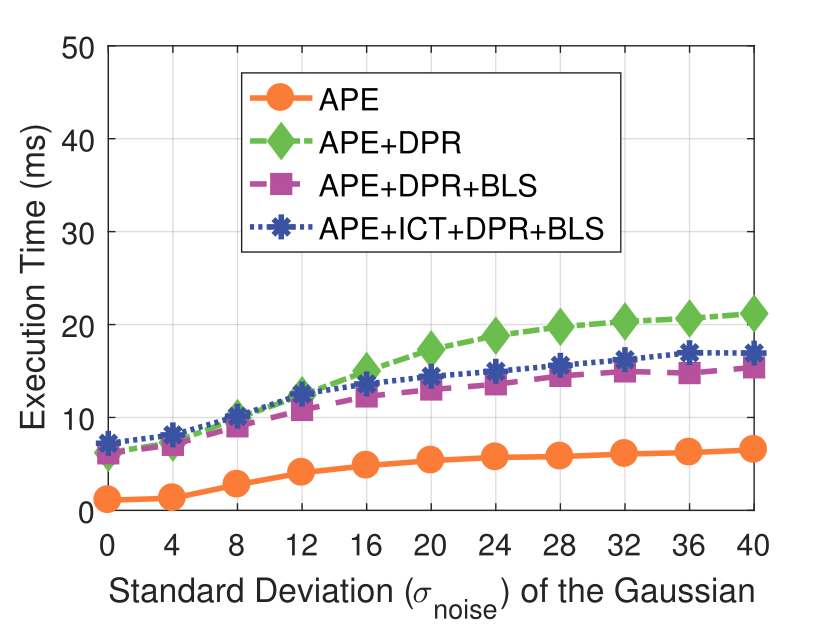
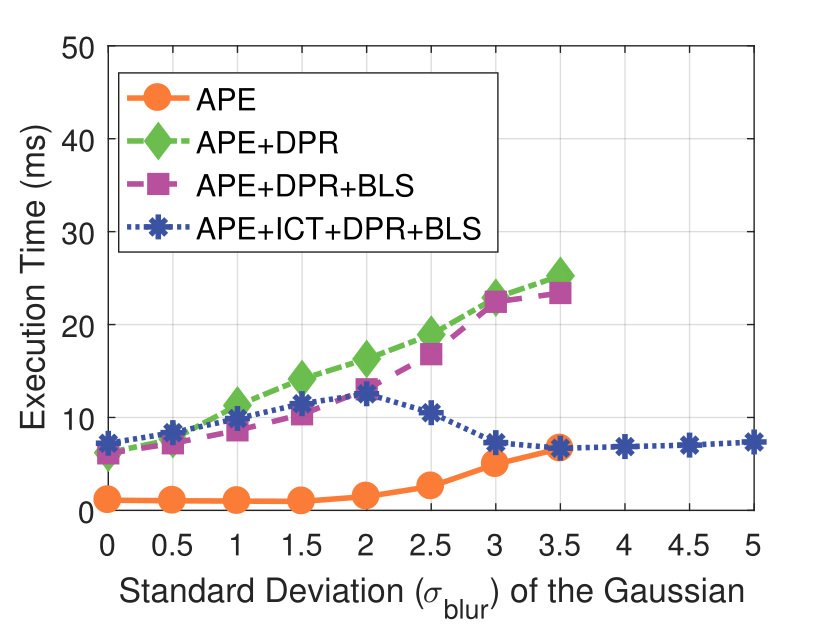
Experimental results on synthetic dataset under four various conditions
with different degradation levels.
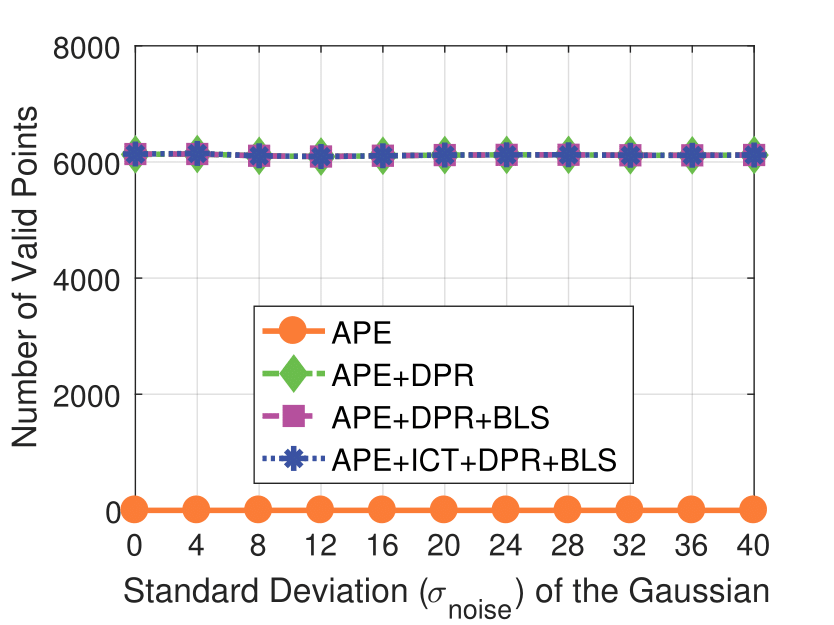
Note that the standard deviation of the Gaussian shot noise is set for an intensity range of 0 to 255.
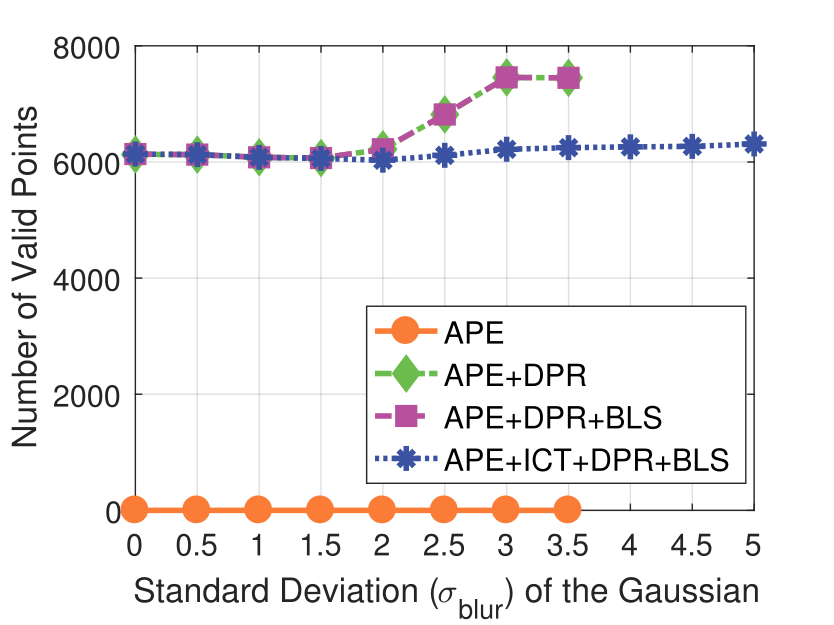
Spatial blur sigma is in pixels for a 1280 ✕ 1024 image.
Shot Noise
Spatial Blur
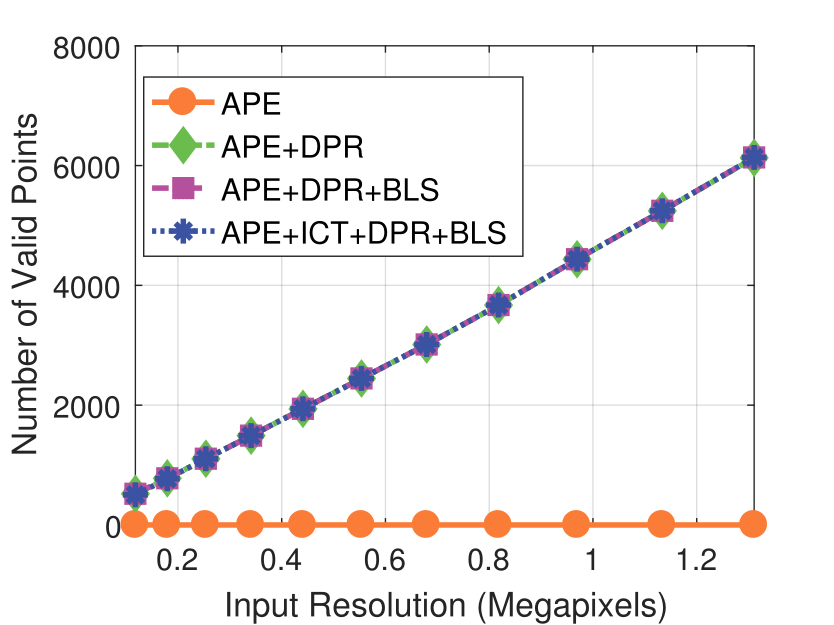
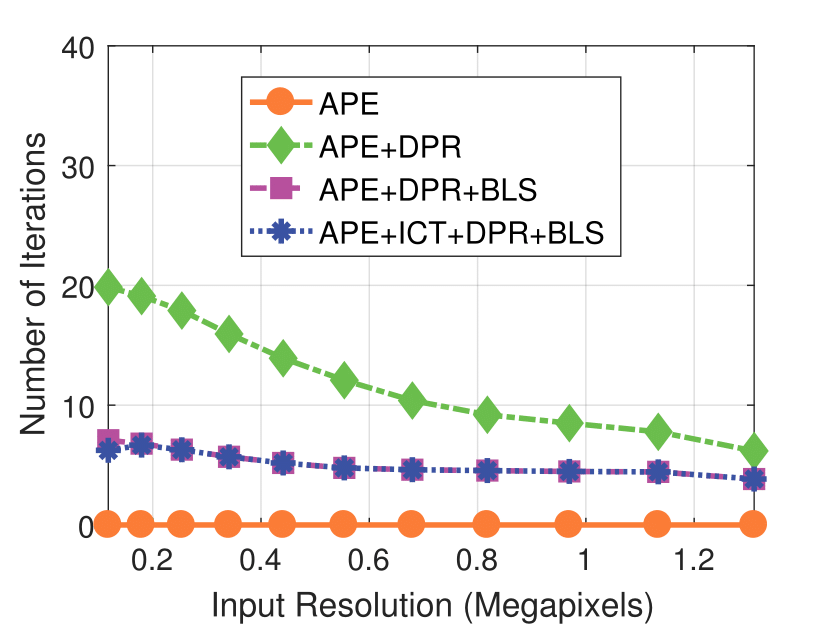
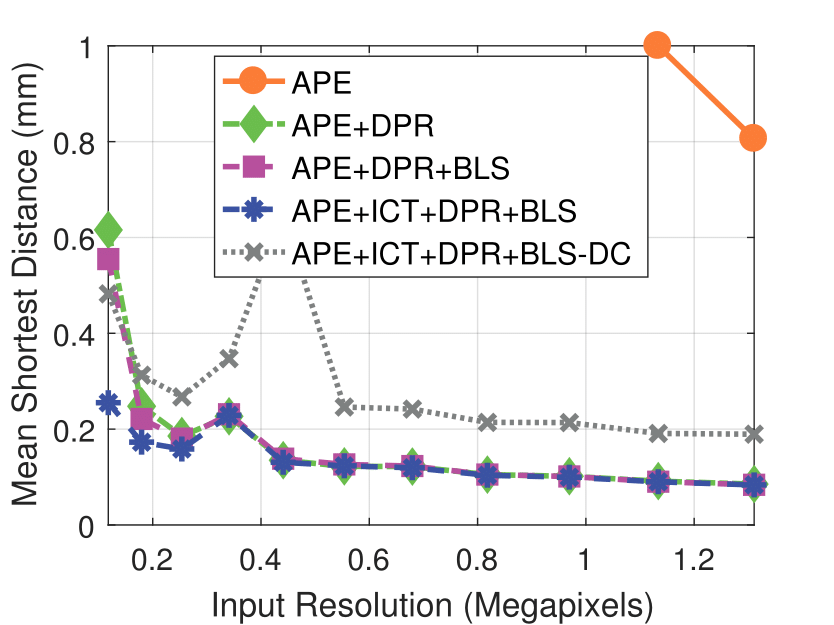
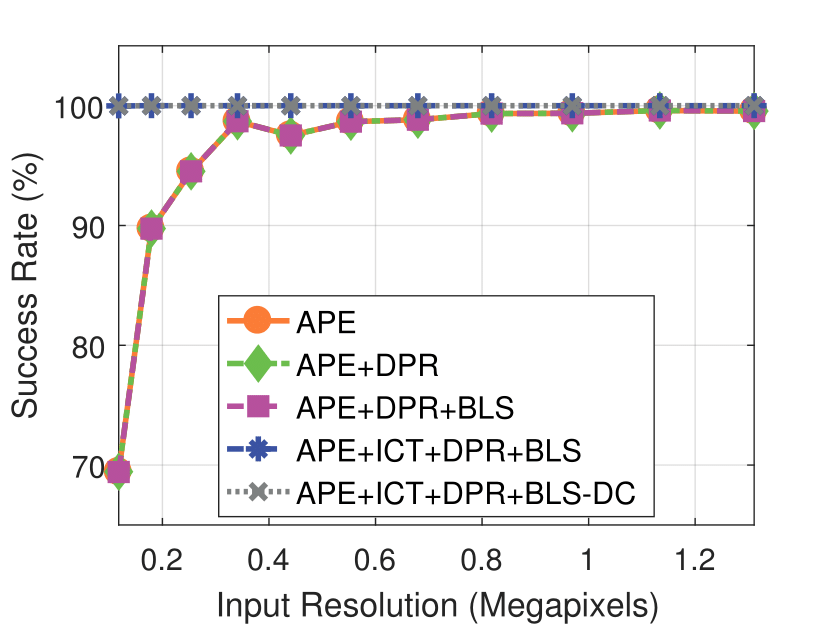
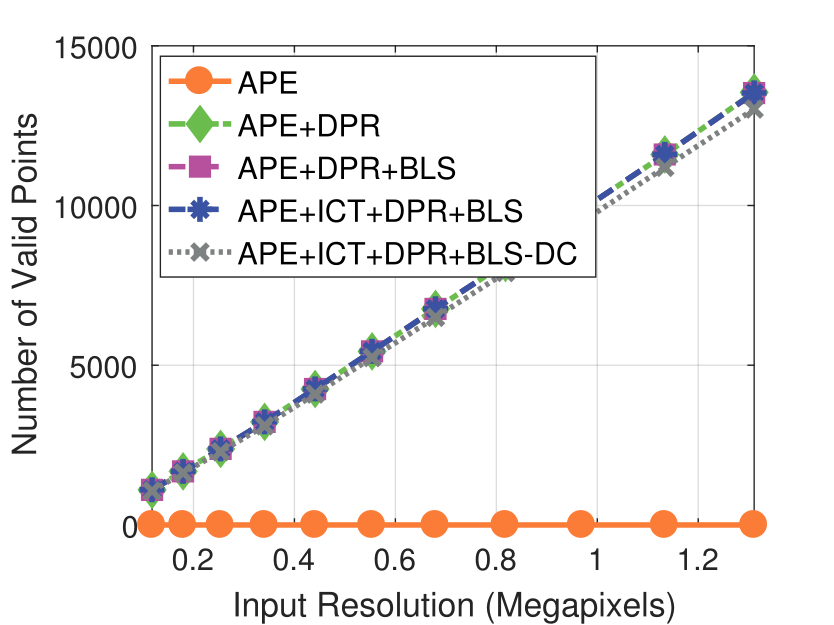
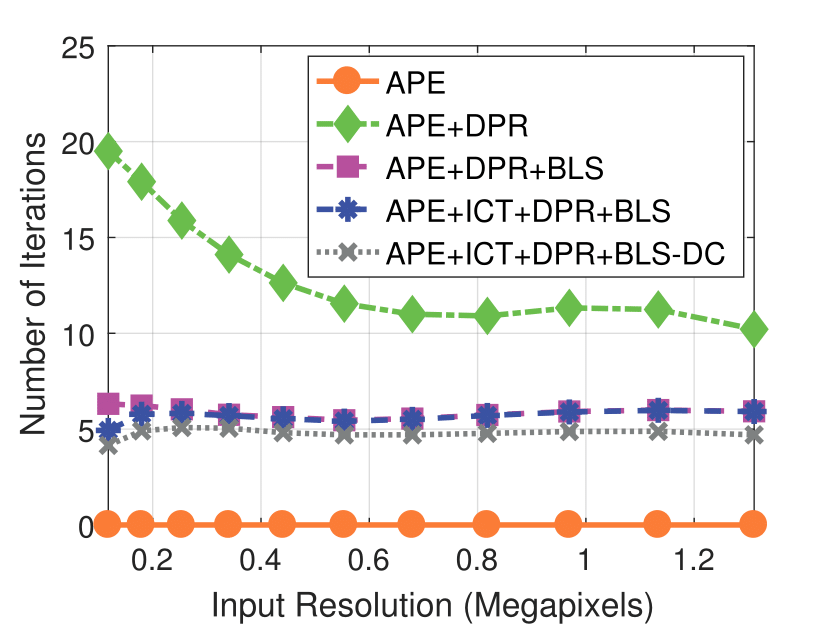
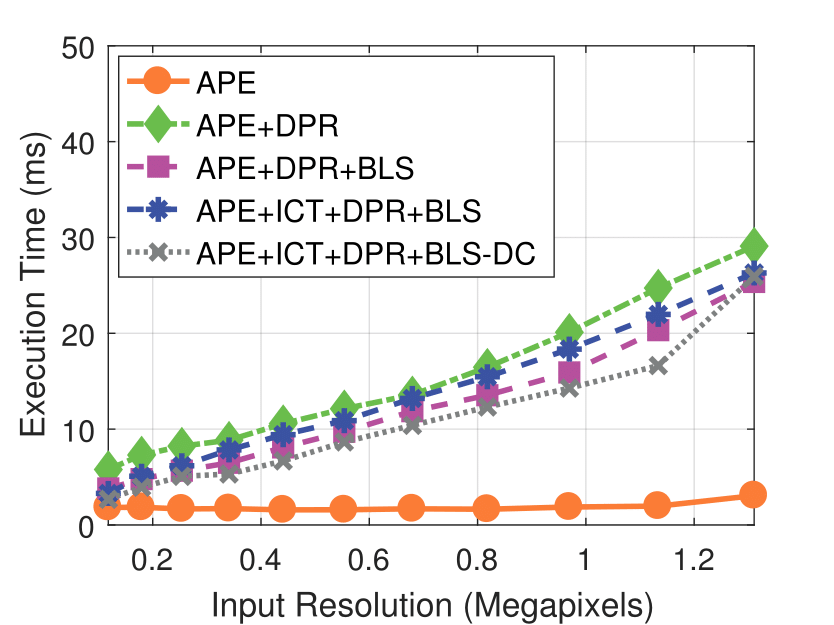
Camera Resolution
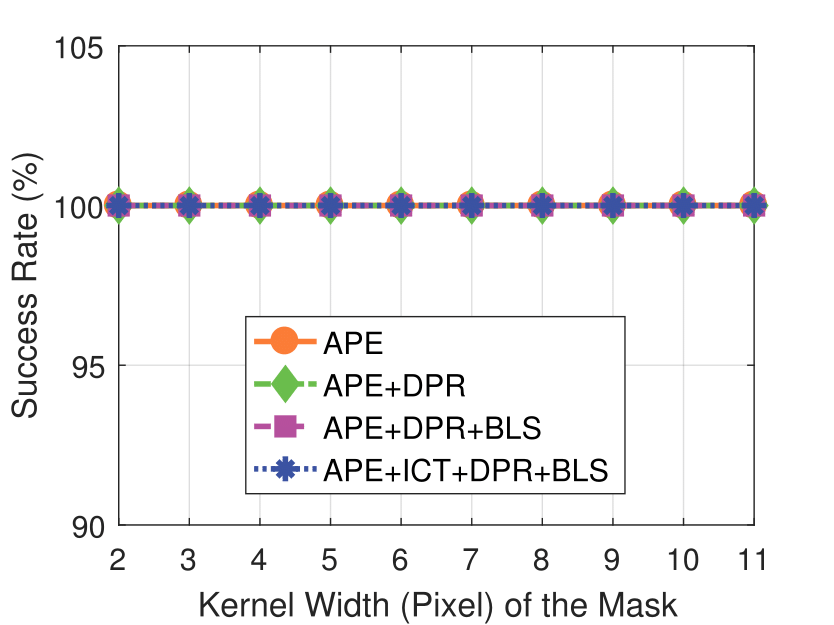
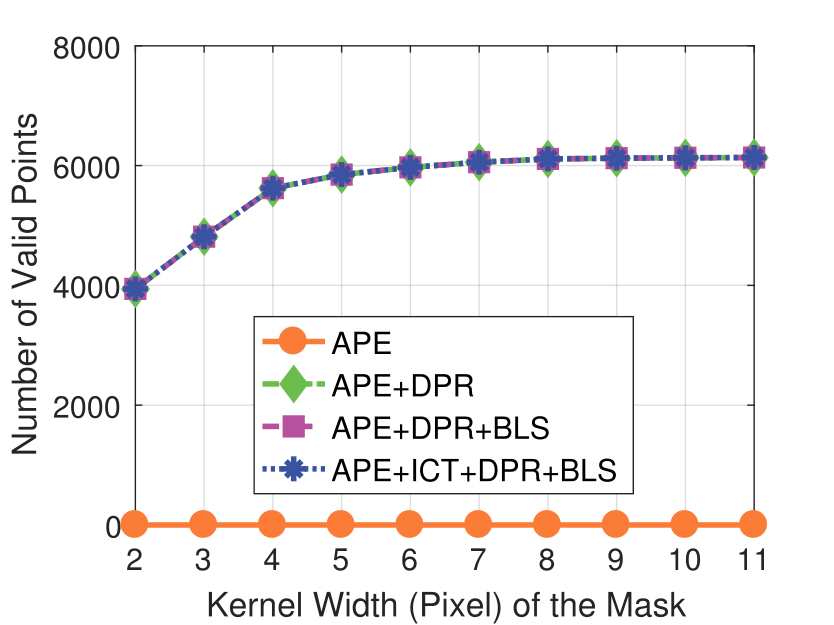
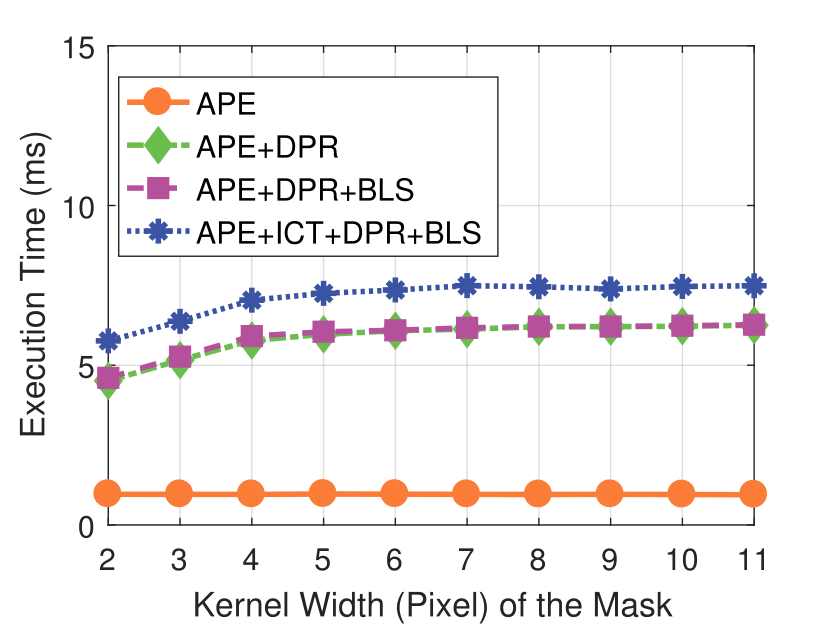
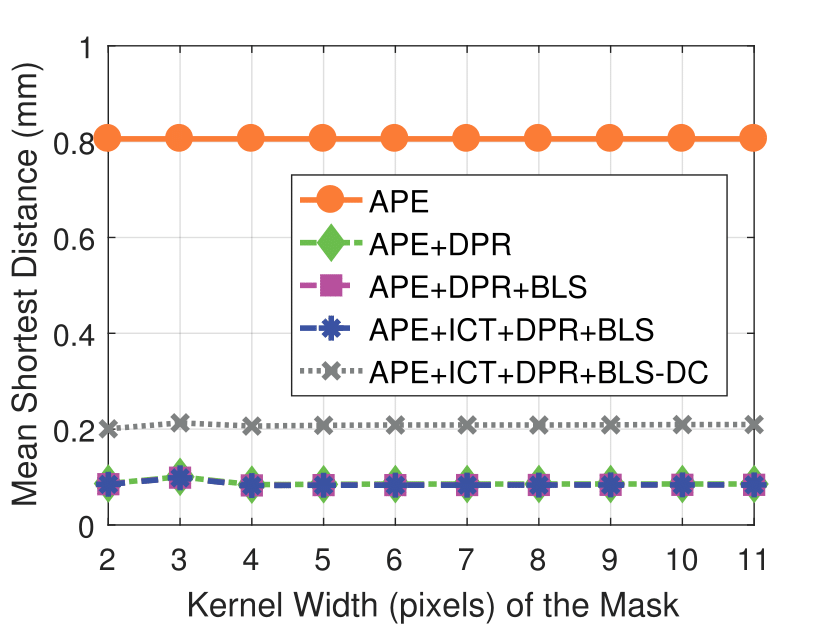
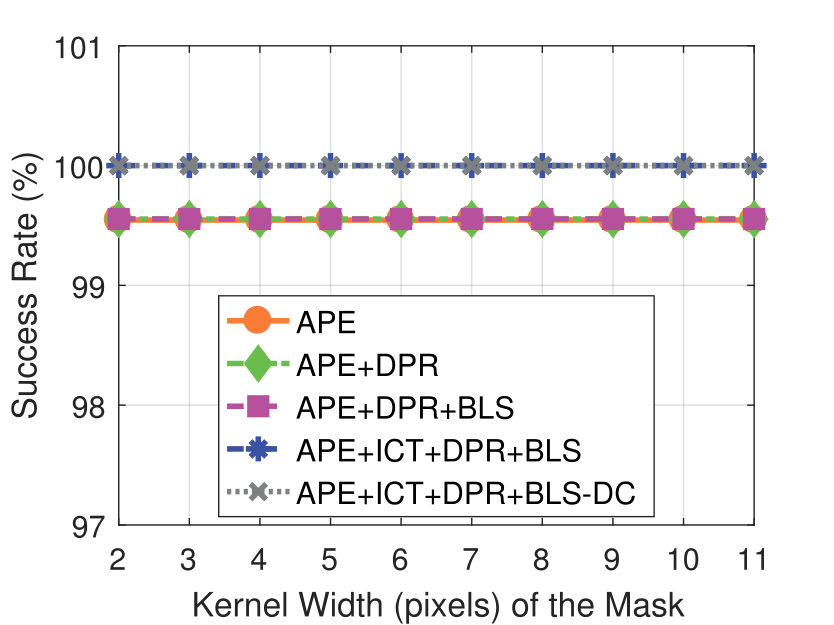
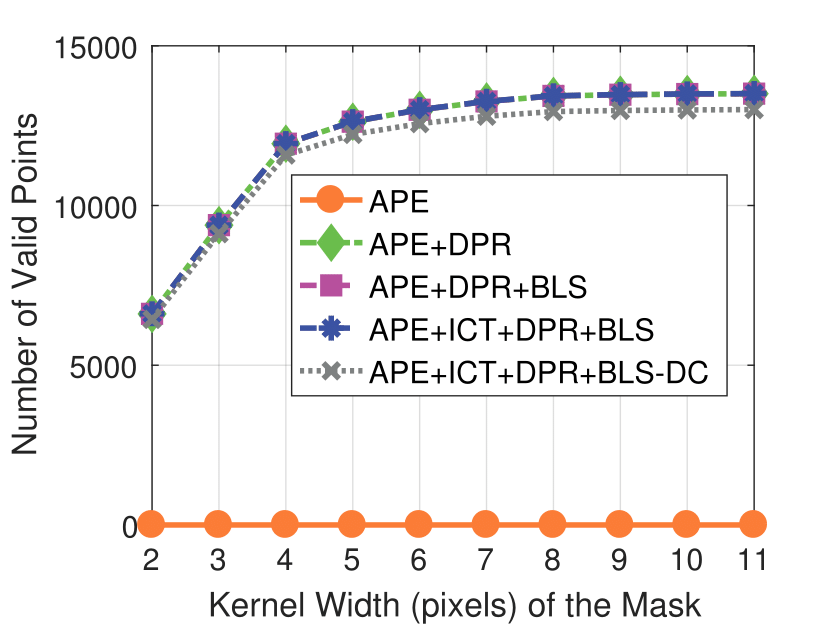
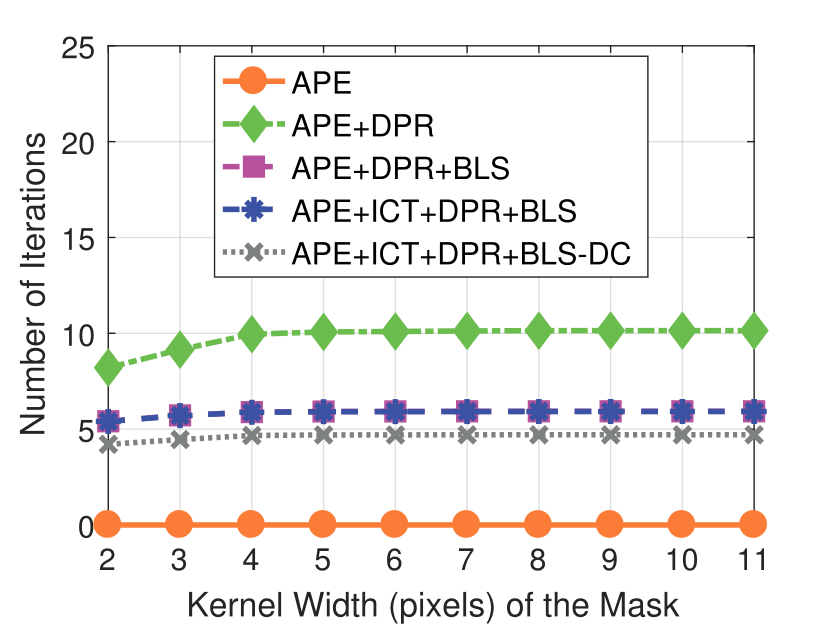
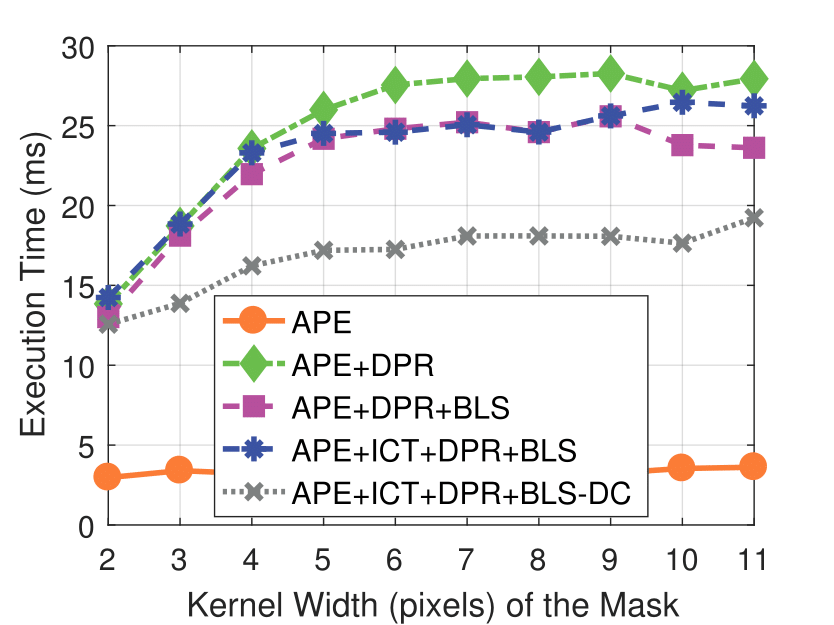
Mask Kernel Width
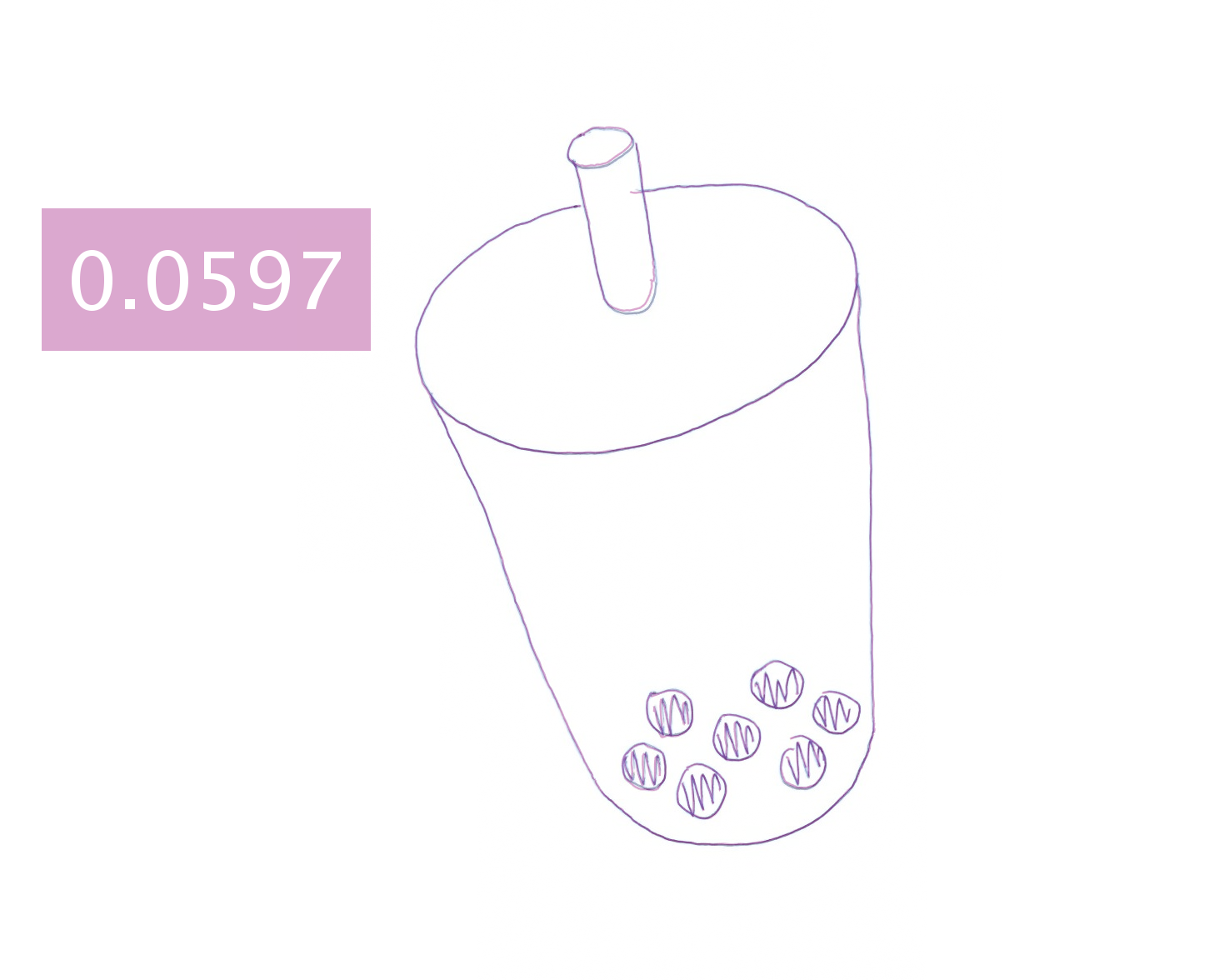
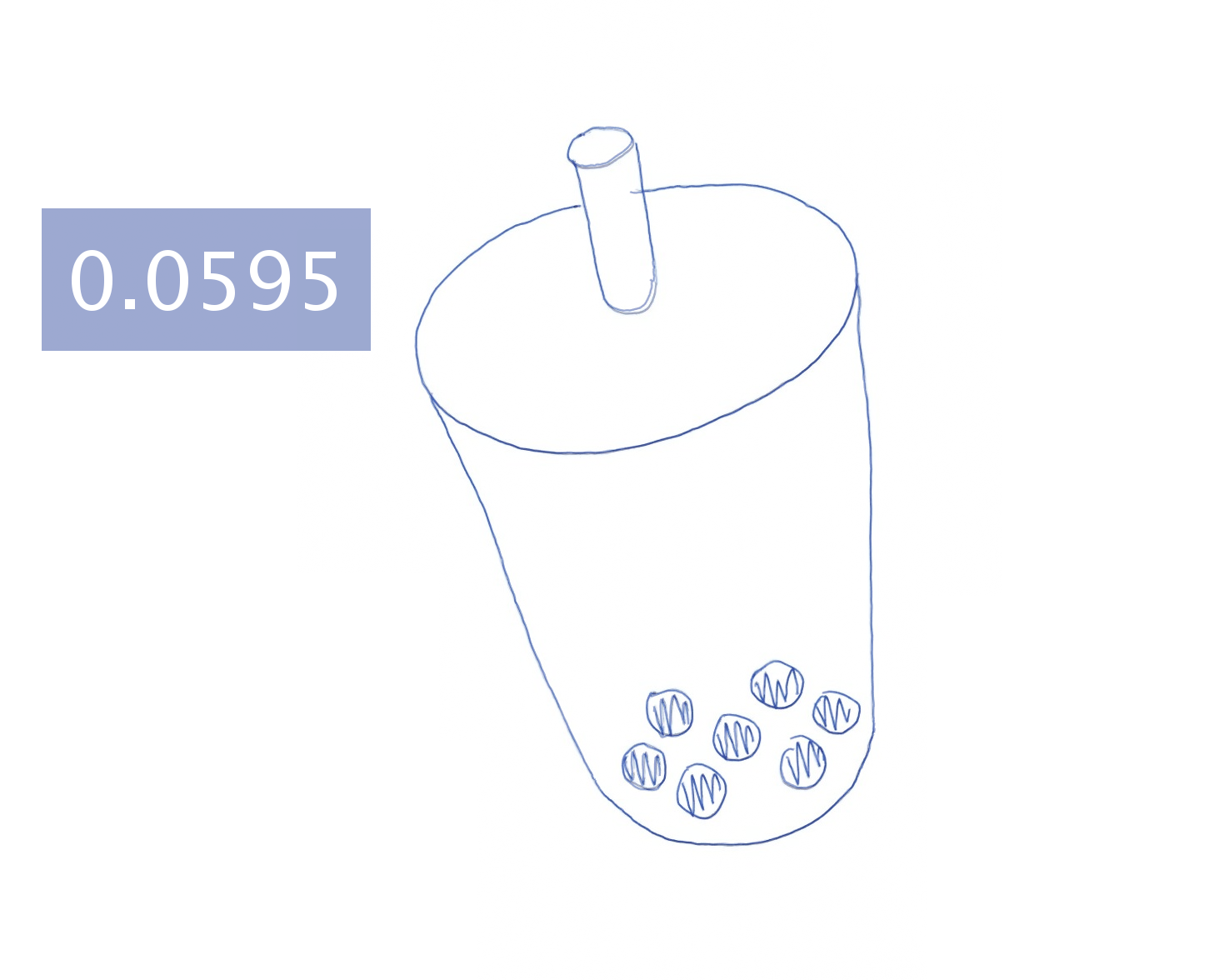
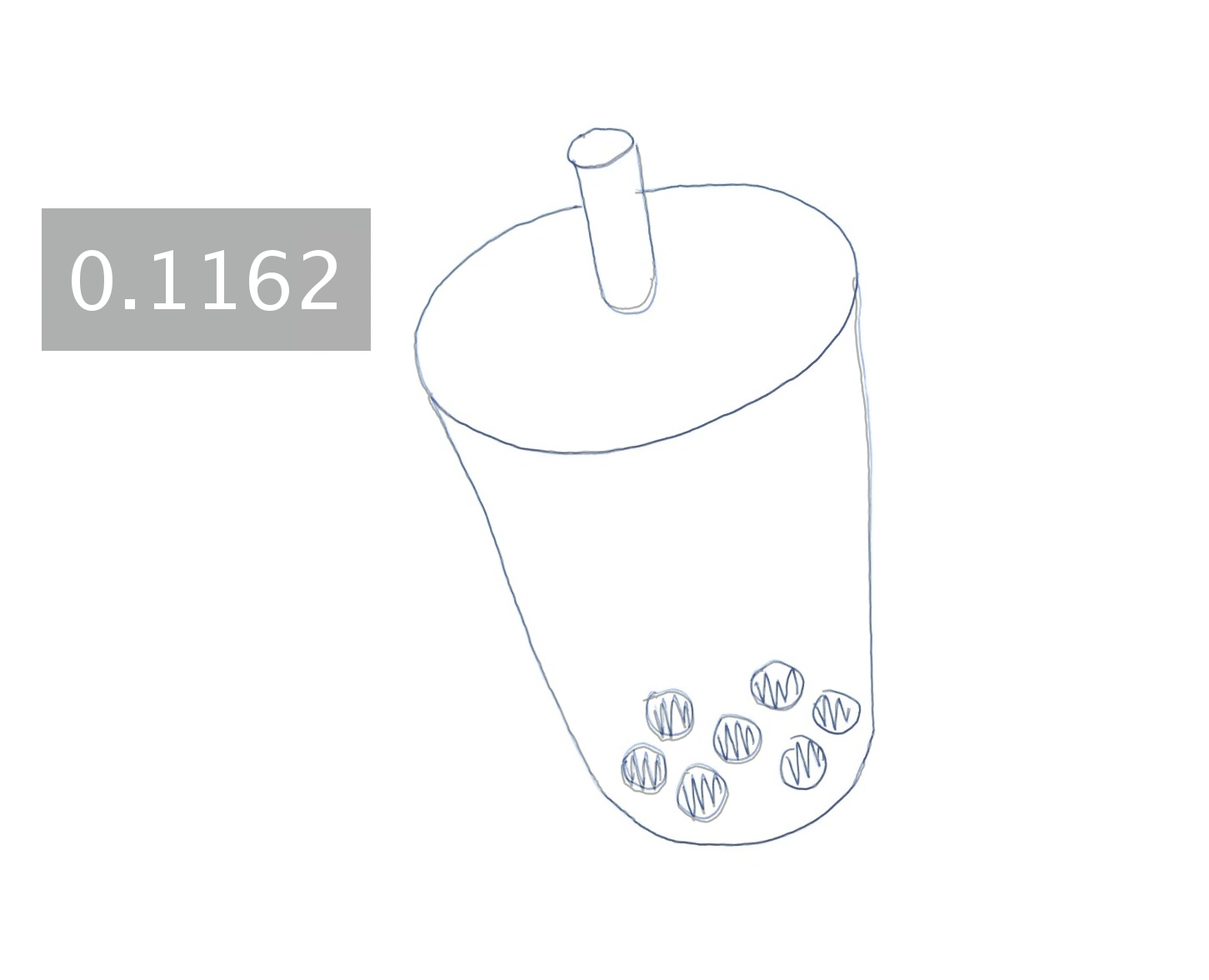
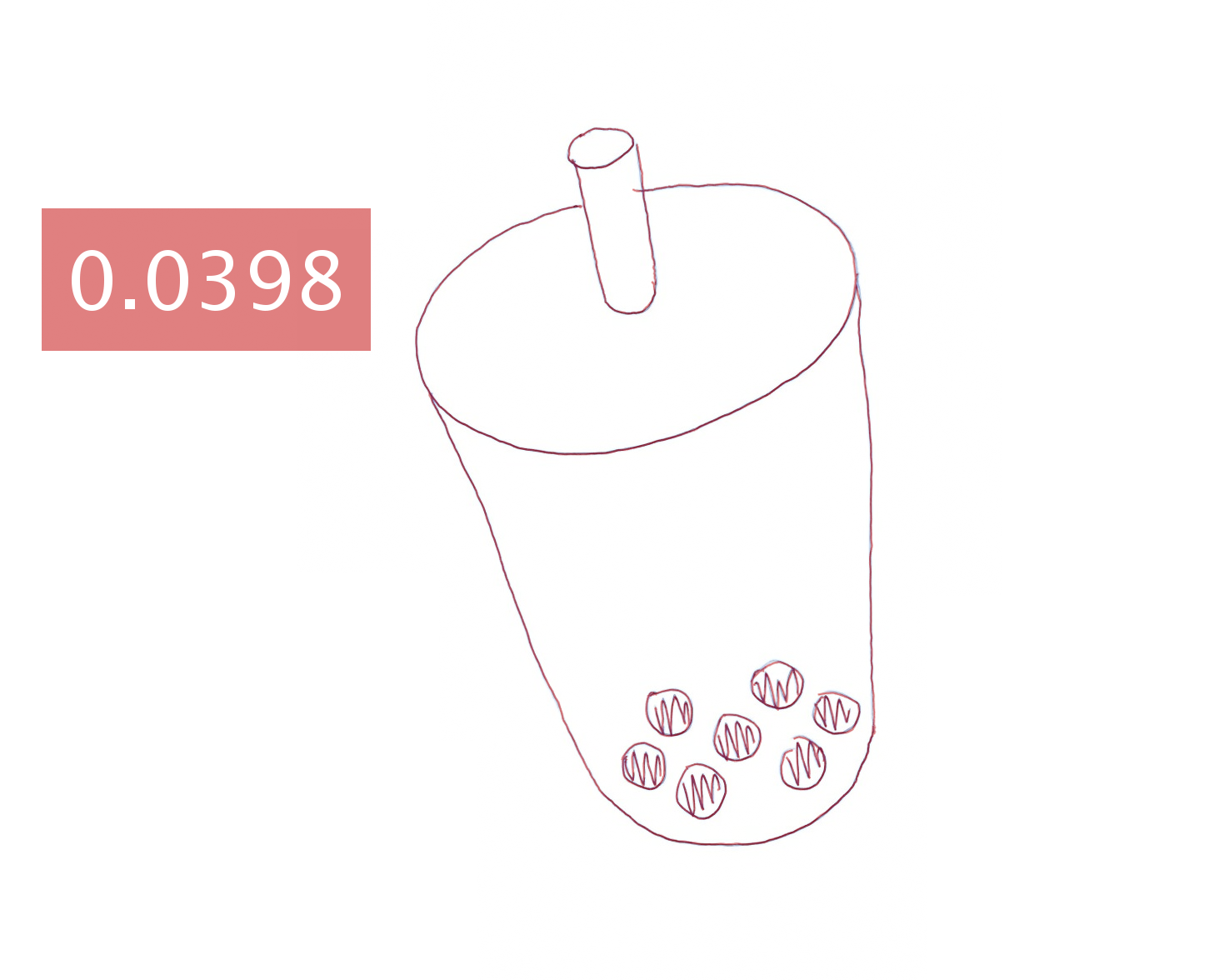
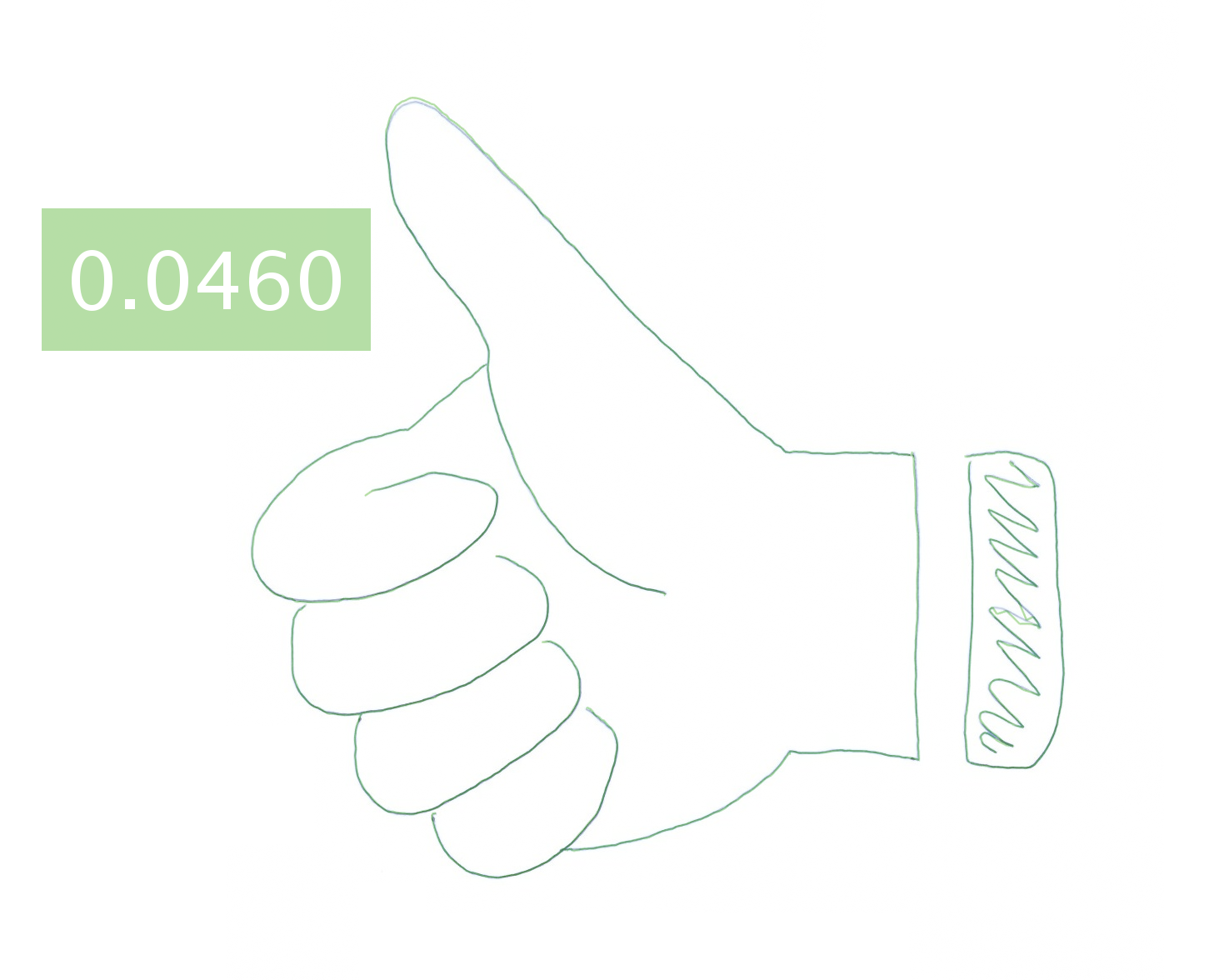
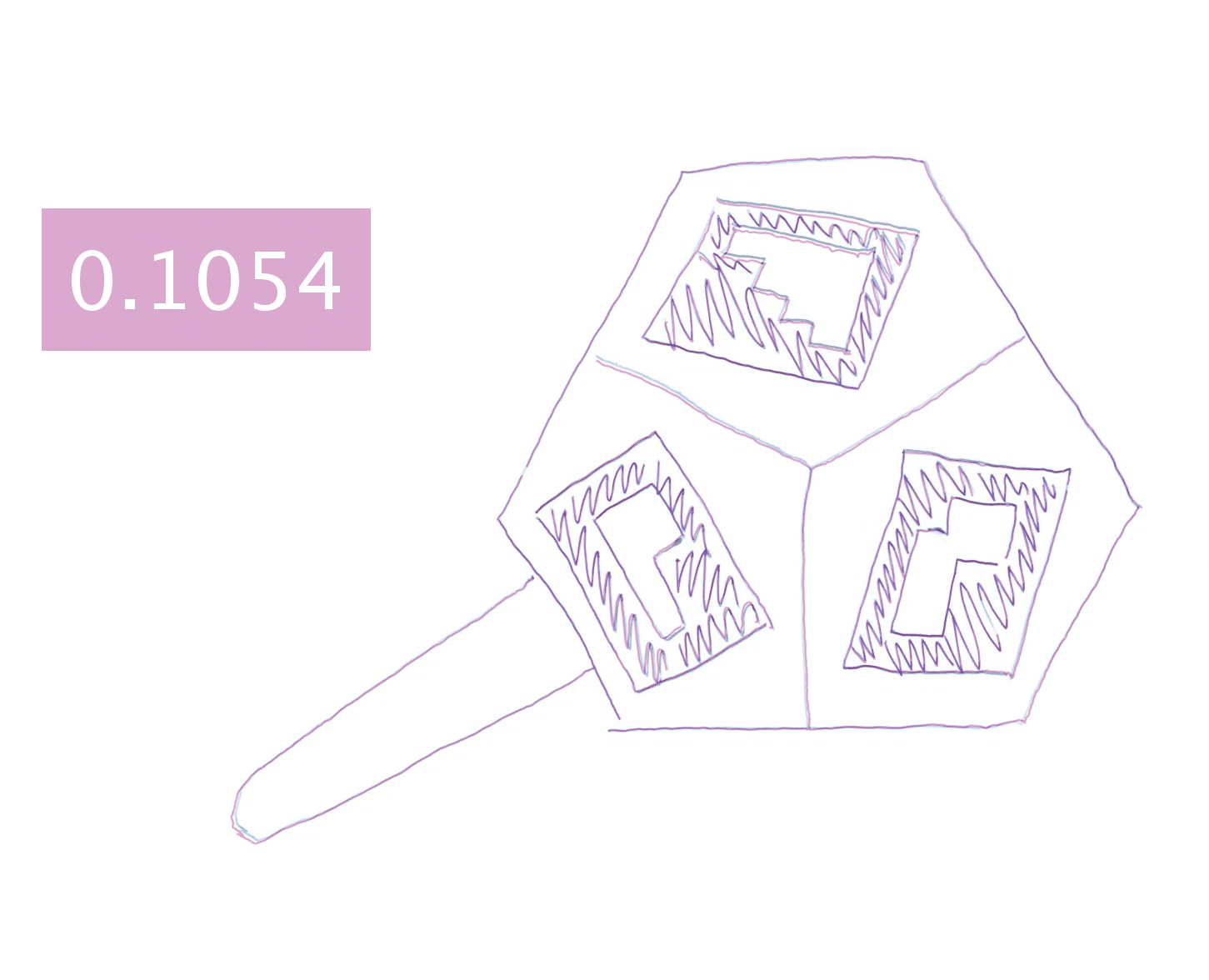
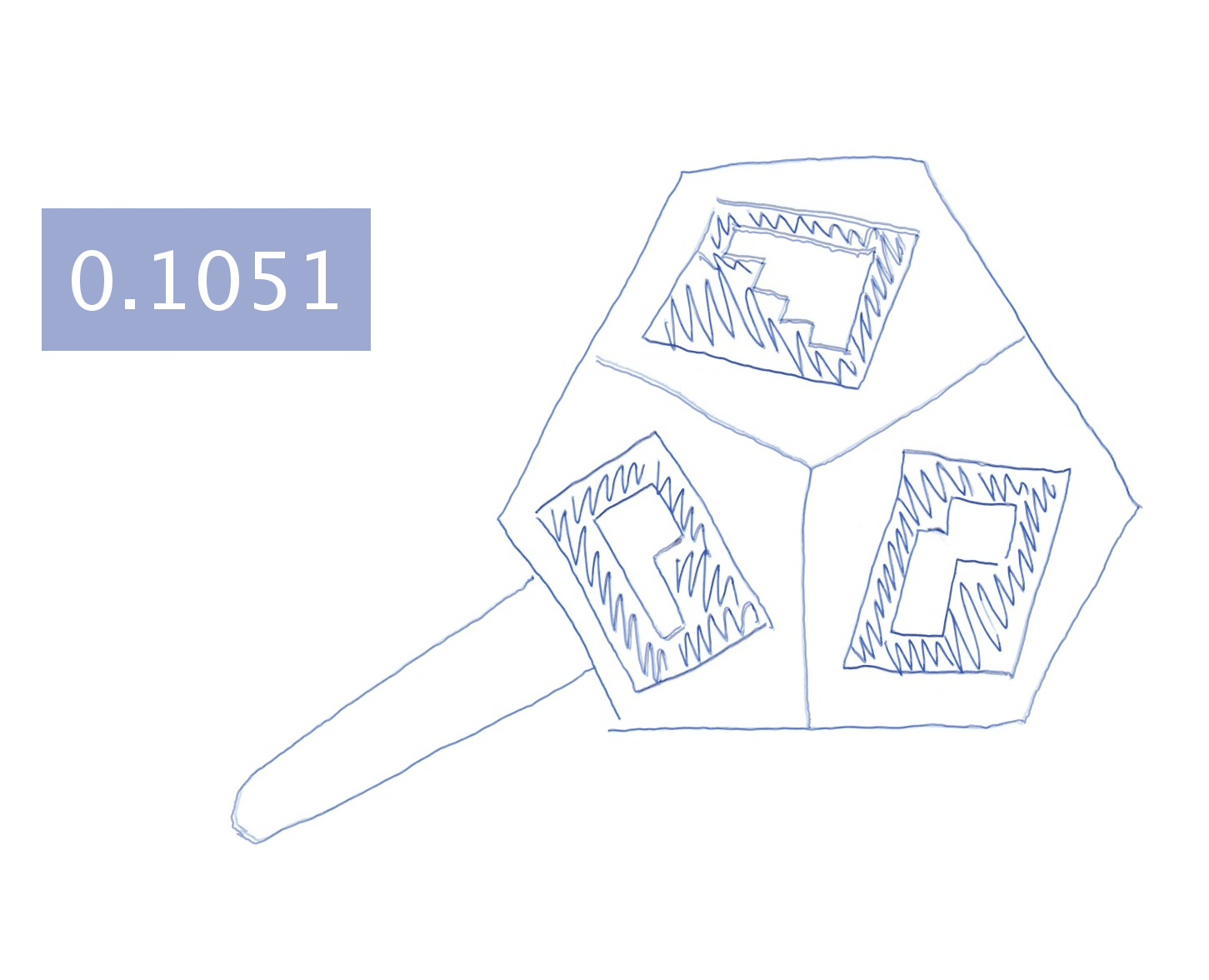
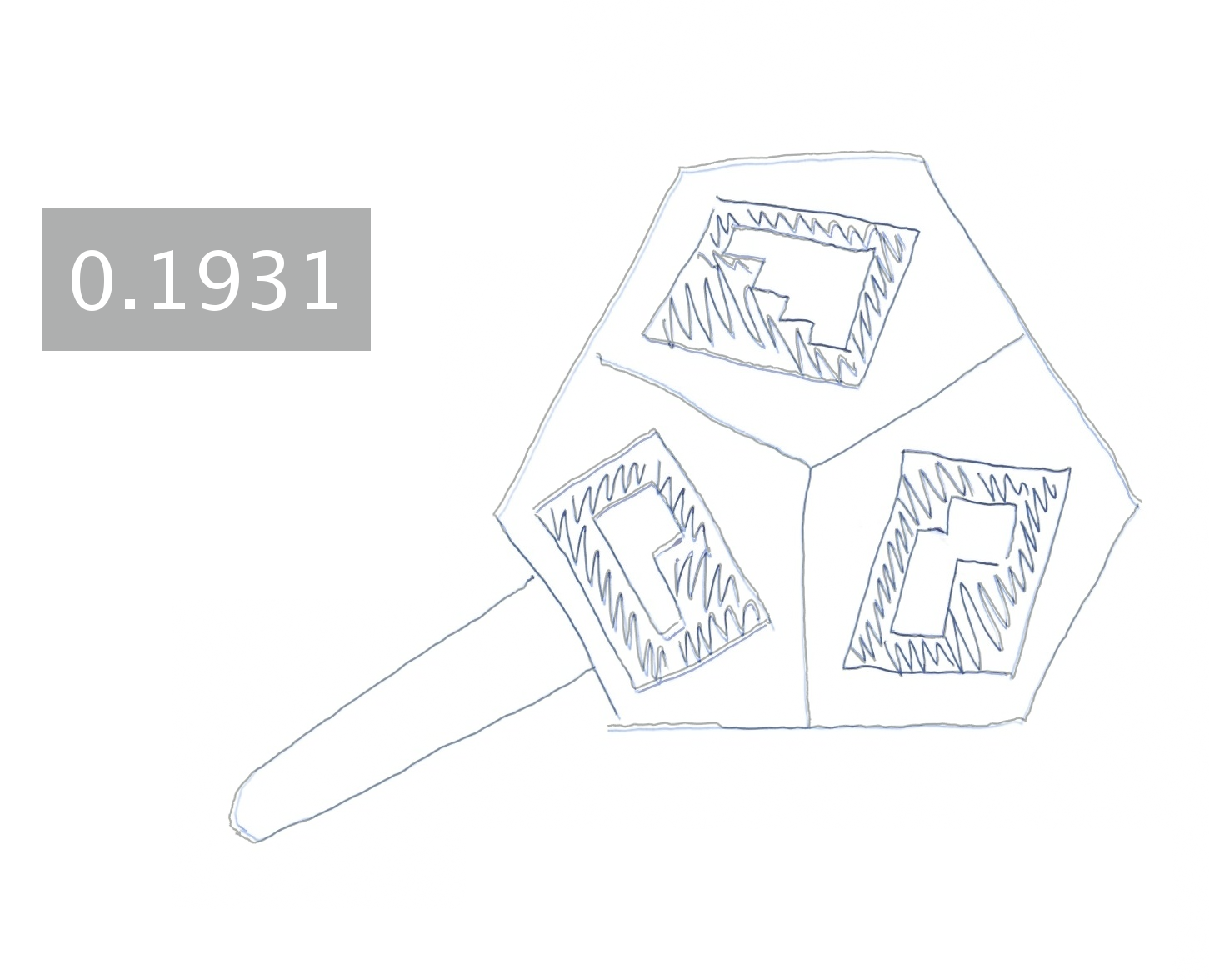
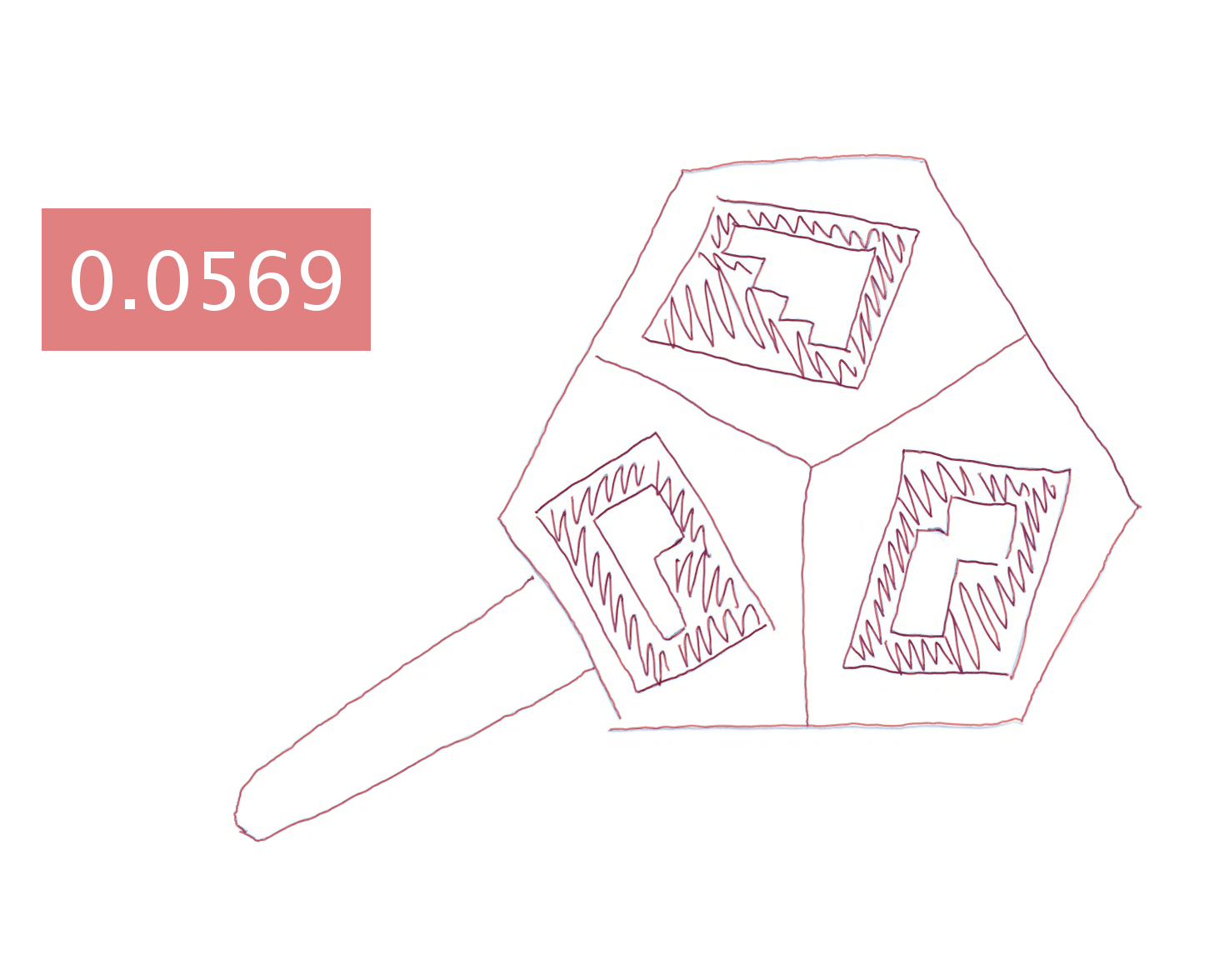
Hand-drawing results generated by different approaches.
Each image is blended with the ground-truth drawing and augmented
with a text box showing the mean shortest distance (in millimeters)
between the generated and ground-truth drawing.
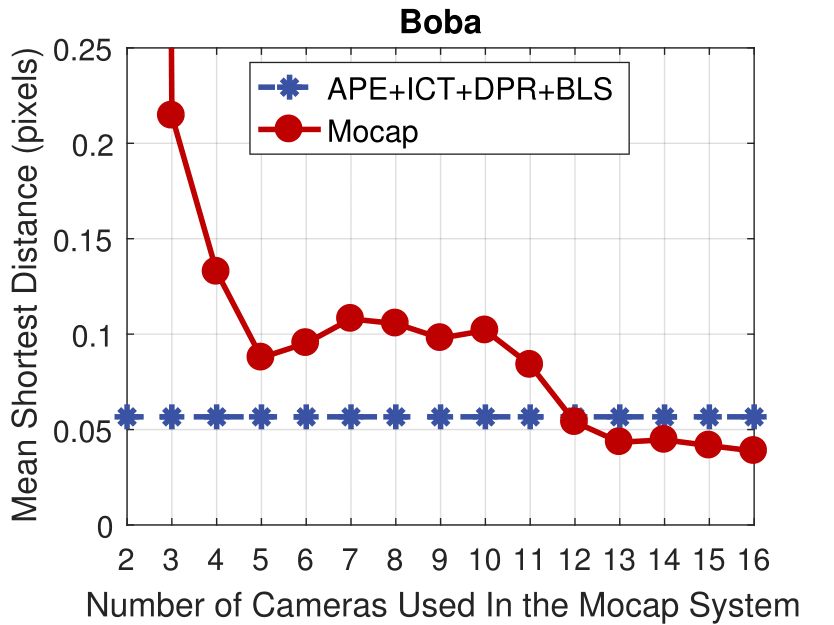
Boba
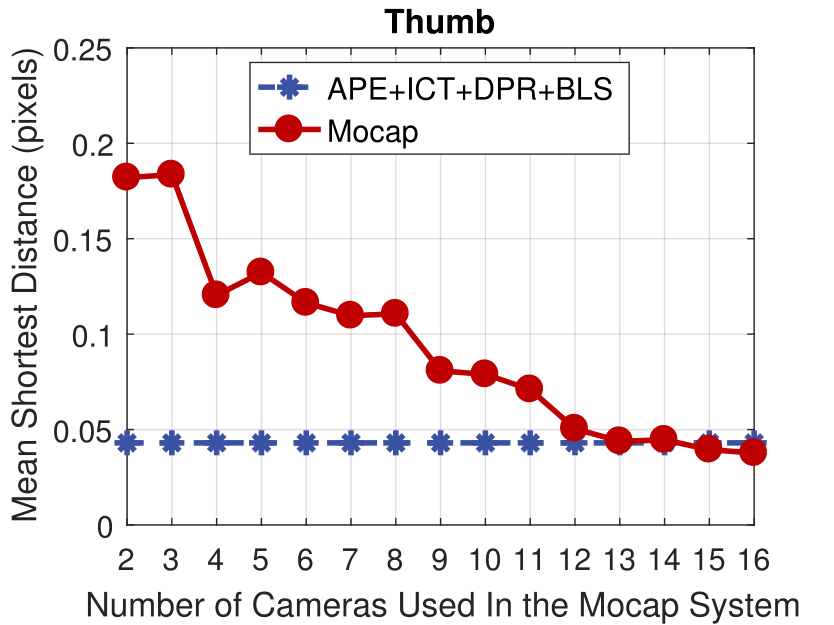
Thumb
DodecaPen
UIST2017
APE
APE + DPR
APE + DPR + BLS
APE + DPR + BLS + ICT
APE + DPR + BLS + ICT - DC
Motion Capture System
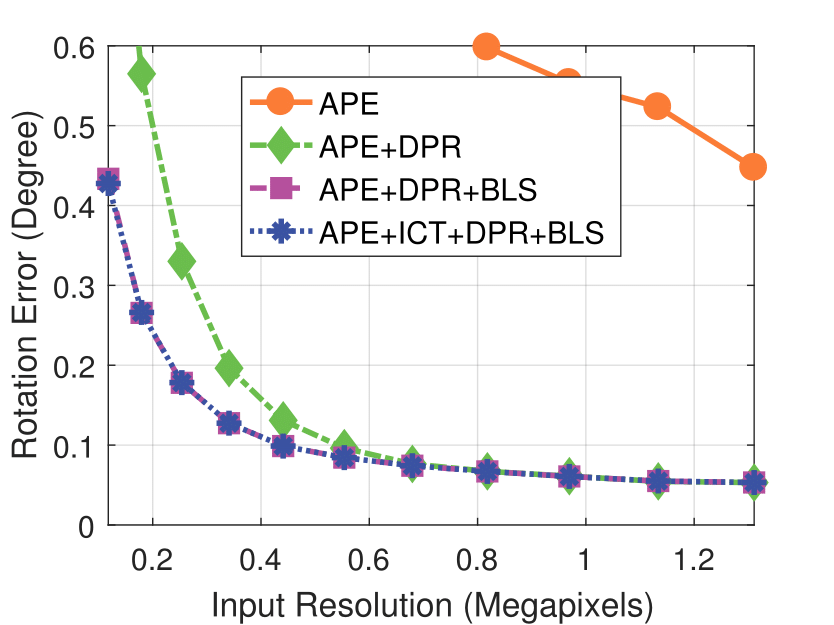
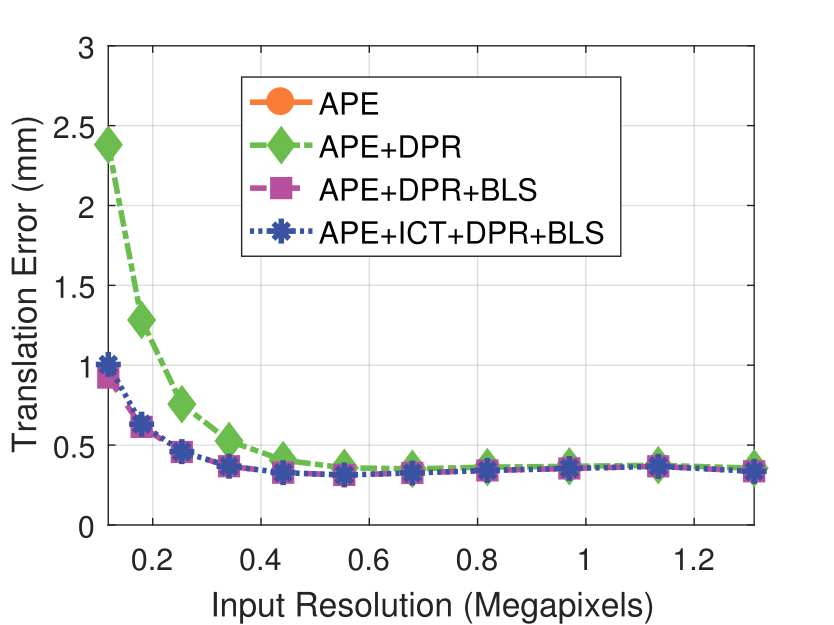
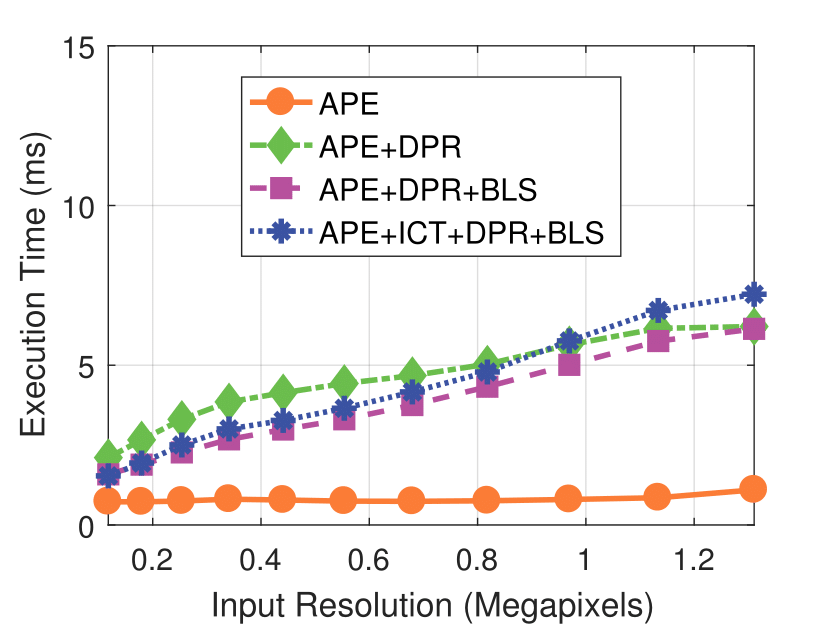
Experimental results on real dataset under various
camera resolution and mask kernel width conditions.
Camera Resolution
Mask Kernel Width
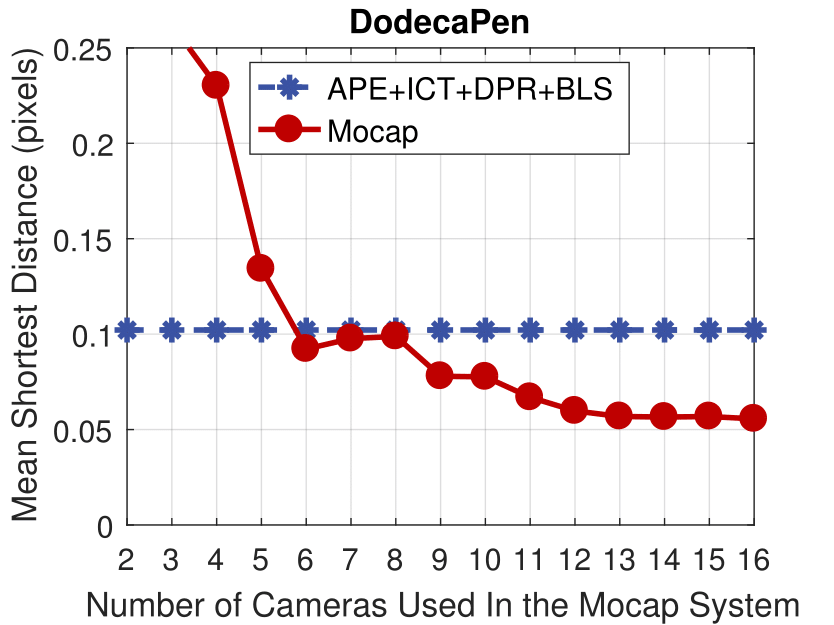
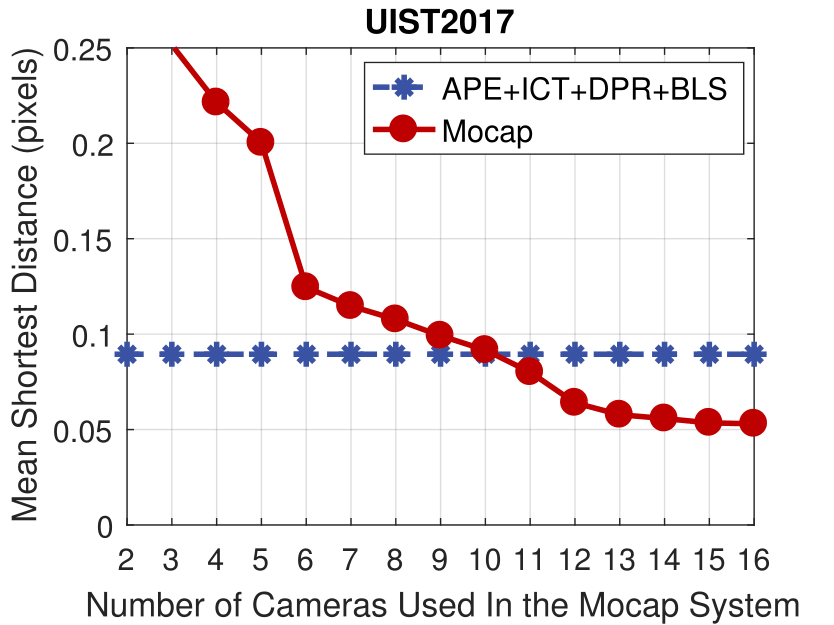
Experimental results of the motion capture system with different numbers of active cameras.
The accuracy of the proposed method is comparable to a motion capture system with 10 active cameras.
We would like to thank
Joel Robinson for generating the dodecahedrons,
Albert Hwang for doing the video voiceover, and
Yuting Ye
for her advice and support throughout this work.